

İleri istatistik kursumuz için 2 haftadan kısa bir süre kalmışken Temel İstatistik ve metodoloji kurslarımızda hep sorulan sorulardan birinin tekrar edileceğini düşünerek bu yazıyı kaleme almaya karar verdim: “SPSS, SAS paralı ve karmaşık. Kolay bir istatistik paket programı önerebilir misiniz?”
Bu sorunun ucuz (hatta ücretsiz) kısmı için uzun süre sadece tek bir yanıtımız vardı: R istatistik programlama dili. Ama bu ücretsiz paket son derece karmaşık komutları öğrenmek için ciddi bir zaman yatırımı içeriyordu. Benim de favorim olan ve neredeyse her işlem için rutin kullandığım MedCalc, döviz kurlarının yükselişi ile ucuz olmaktan yavaş yavaş çıktı. Üniversiteler tarafından verilen ücretsiz SPSS ve SAS ağ sürümleri ile Kadıköy Yazıcılar iş hanı çözümlerini saymazsak kendi temel analizlerini yapmak isteyen klinisyenler için alternatif kalmamıştı.
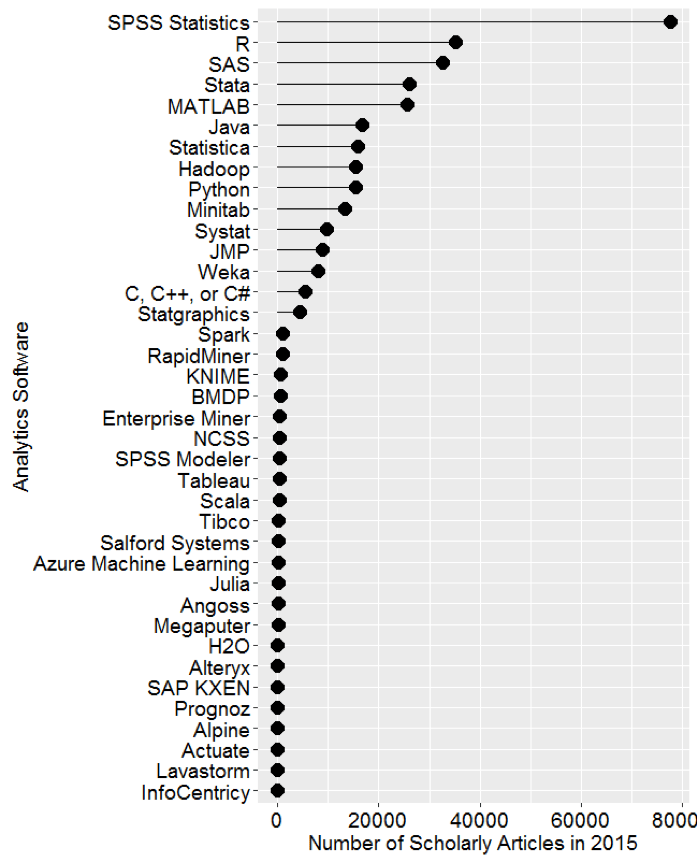
Muenchen ve ark tarafından 2015 yılında yayınlanan analize göre (RA Muenchen, 2015, http://r4stats.com/articles/popularity) en popüler analiz yazılımı istisnasız SPSS.[1] Ama R korkunç bir hızla yükselerek neredeyse SPSS’i yakalamış vaziyette. Bu analizde R paketinin kolaylaştırılması ve kullanımının yaygınlaştırılmasına yönelik bazı “üst” programlar da eklenmiş durumda. Bunlardan en önemlileri Jamovi[2] ve JASP[3]. Jamovi biraz daha görsel ve daha kolay ama ikisi de çok benzer. İkisi de R istatistik programlama dili üzerine yazılmış, aslında R paketlerini kullanan ama görselleştiren birer üst paket ve birbirini tamamlayan fonksiyonları mevcut.
Jamovi (www.jamovi.org)
Jamovi, R üzerine yazılmış, sadece tıklama ile tüm fonksiyonların yerine getirilebileceği ve neredeyse başka hiçbir paket gerektirmeyecek, tamamen ücretsiz bir program. SPSS .sav dosyalarını açabiliyor. Bunun dışında .csv ya da .txt dosyalarını da açarken hiç sorun yaşatmıyor. Eğer Excel’e kaydettiğiniz verileriniz varsa Save As… diyerek .csv formatında kaydedip rahatlıkla Jamovide açabilirsiniz.

Boş bir Jamovi açtığınızda 2 ekranlı bir yapı göreceksiniz. Solda Excel usulü bir veritabanı kısmı, ve sağda dökümler ve grafiklerin canlı canlı görüneceği ekranımız. Ortadaki sütundan tutarak sola sağa bunların boyutlarını değiştirebilirsiniz.
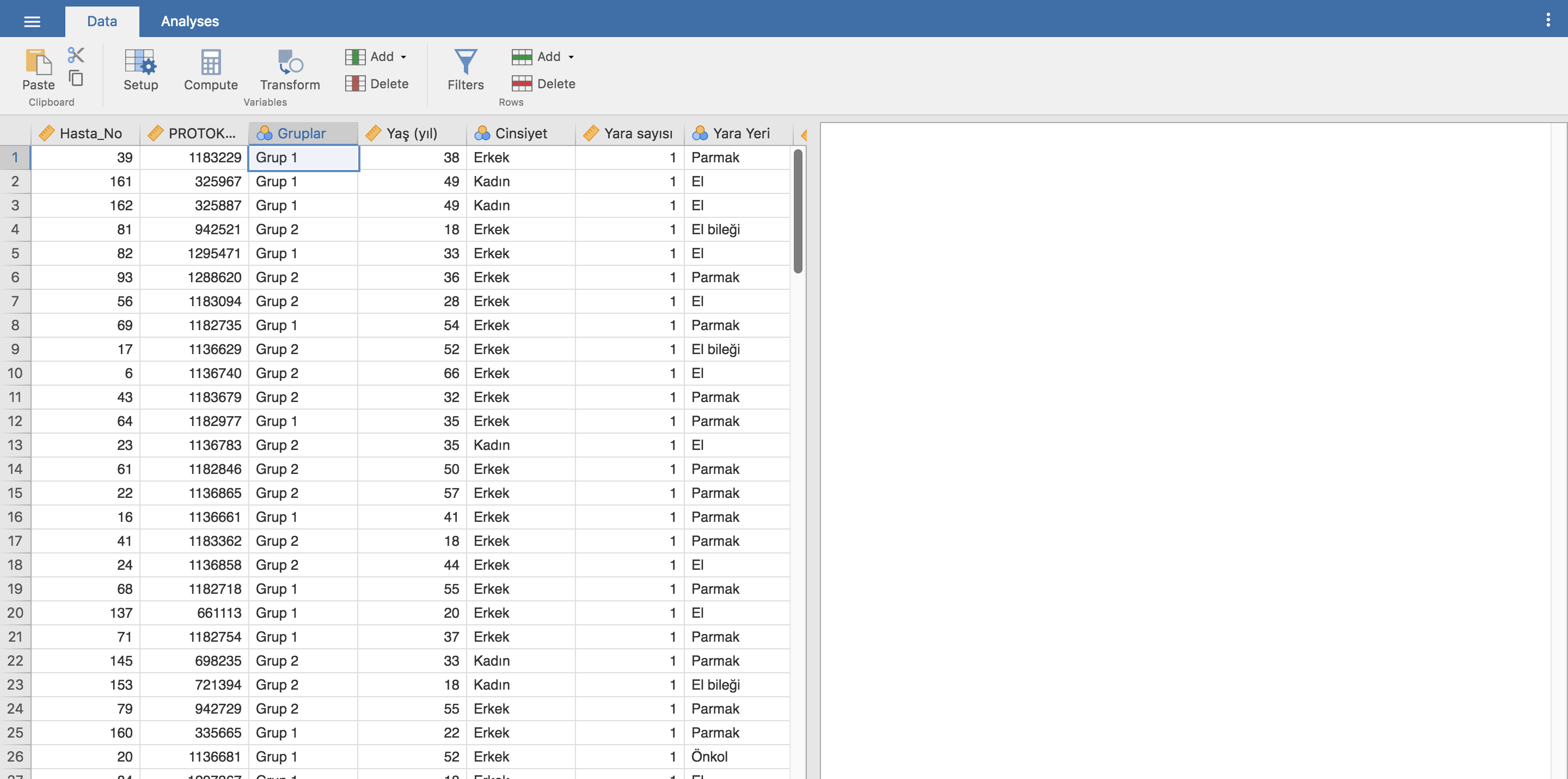
Jamovi, yukarıda Data ve Analyses olmak üzere 2 tab bulunan sadece iki kurdele menüden ibaret. Sütunlar değişkenlere satırlar vakalara ait. Her sütunun başında değişken isminin yanında değişken tipini işaret eden bir de görsel var. Sütun başlığına 2 kez tıklayarak değişken ayarlarını açabiliyoruz:
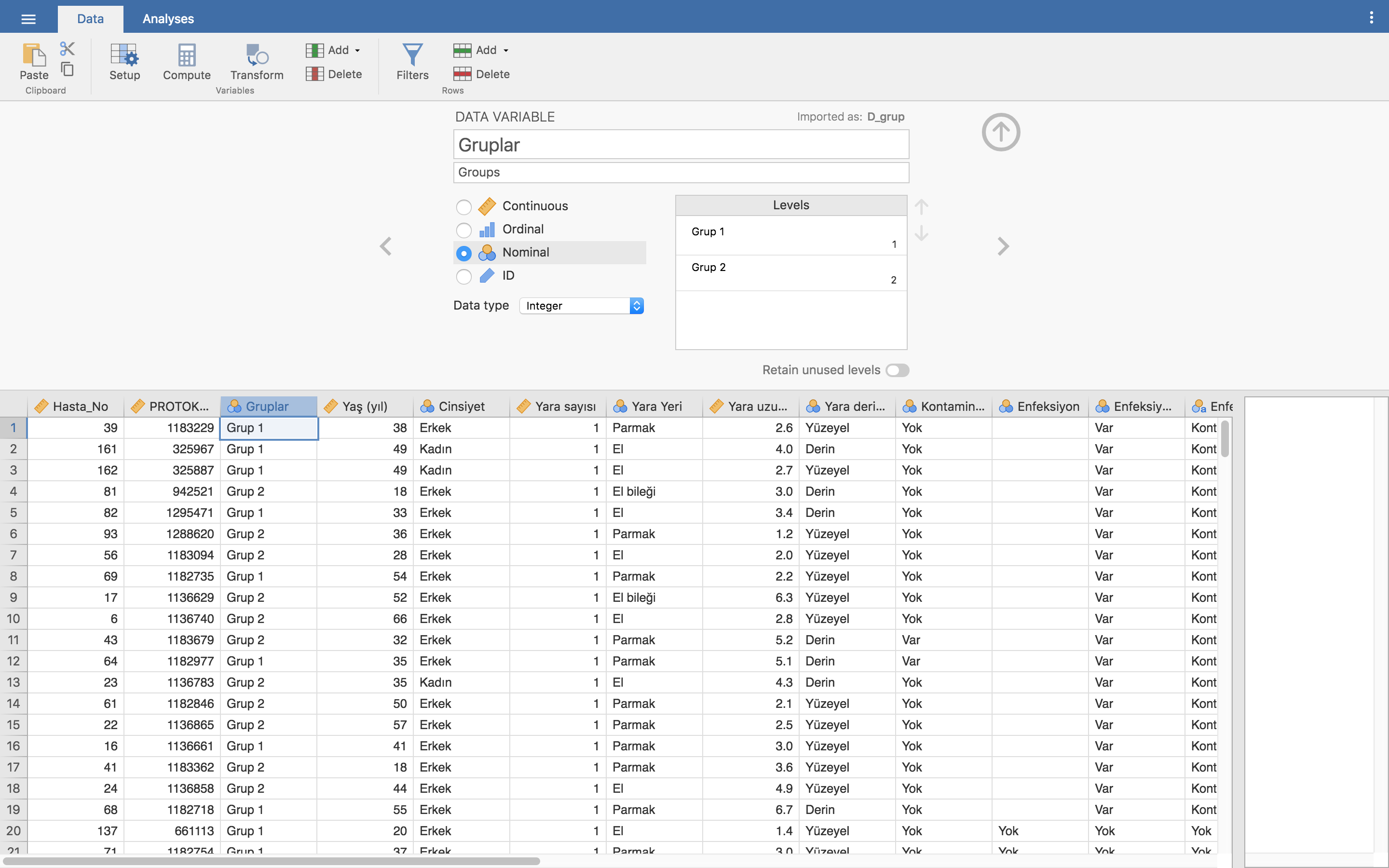
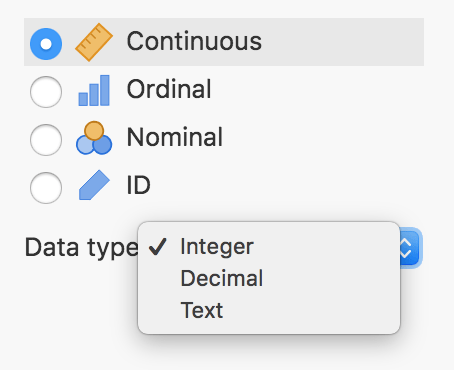
Bu kısımda değişken ismi ve etiketini değiştirebiliyoruz. Değişken tipini sürekli (continuous) ve kategorik (ordinal ya da nominal) olarak seçebiliyoruz. Ayrıca sıra numarasını ifade eden ID değişkenini de belirleyebiliriz. Veri tipi olarak değişkenin ne içerdiğini heman altında aşağı açılan menüden belirliyoruz. Eğer değişken tipi olarak kategoriklerden biri olan ordinal ya da nominali seçersek, o değişkenin aldığı tüm değerler Levels kısmında sağda veriliyor. Eğer kategorik bir değişken ise buradaki sayıların üzerine tıklayarak o sayının karşılık geldiği kategorinin ismini yazmanız mümkün.
Değişkenlerin hepsini bu şekilde programa tanıttıktan sonra Analyses tabına geçebiliriz.
Tanımlayıcıların dökümü
İlk seçeneğimiz Exploration… Bu menünün altındaki tek seçenek Descriptives… Tanımlayıcı istatistiklerimizi buradan dökeceğiz.
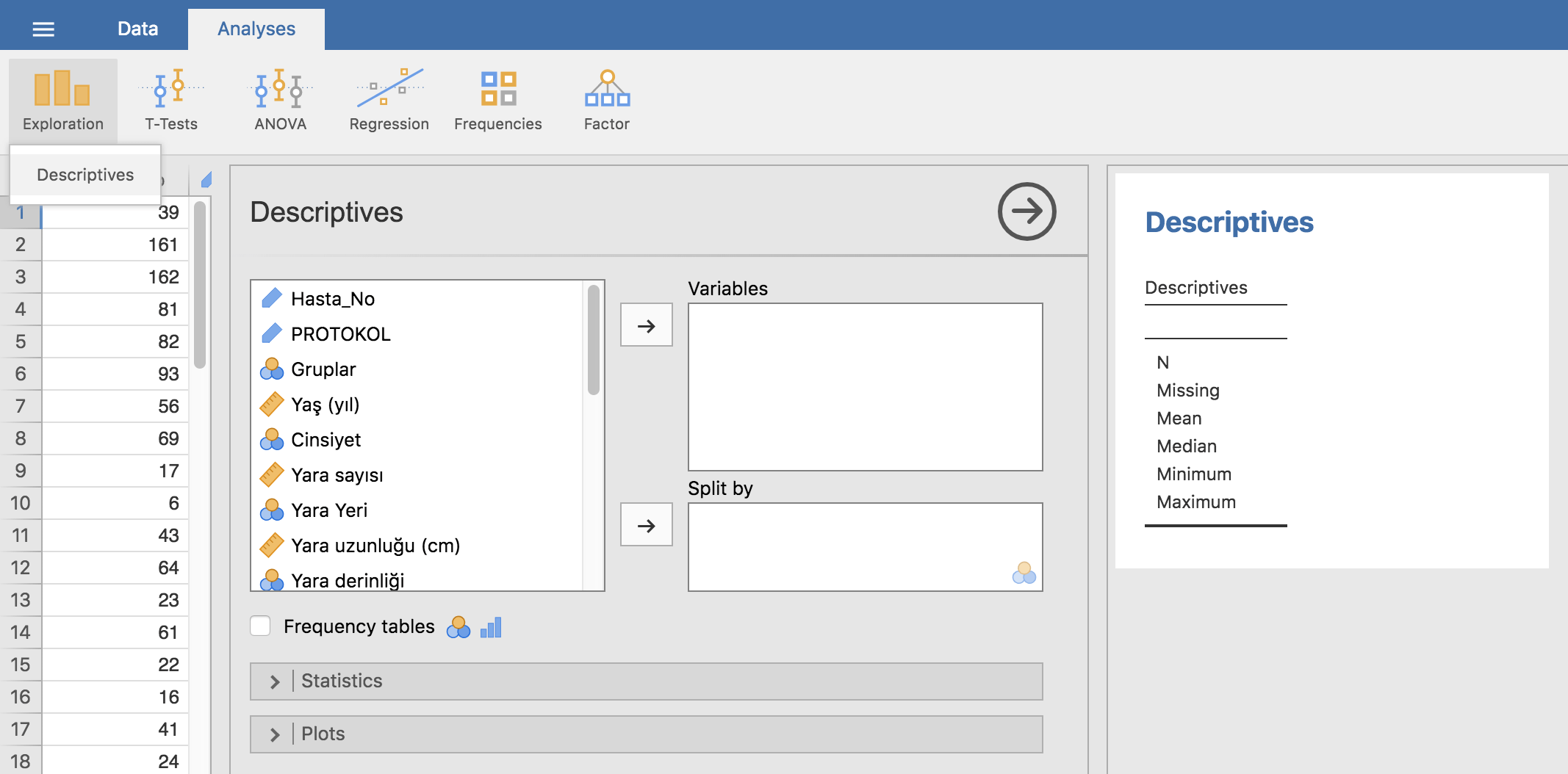
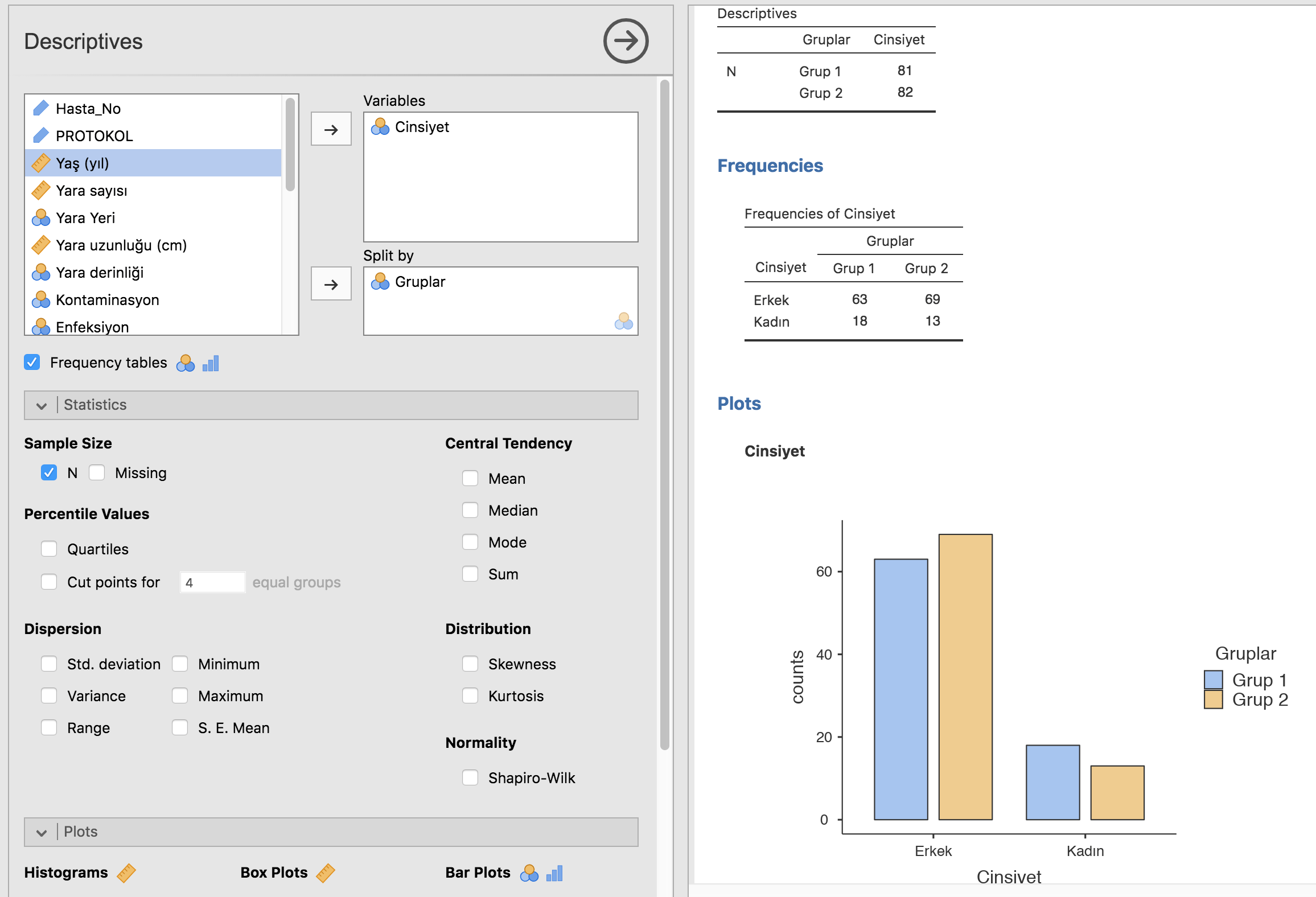
Bu seçeneği seçtiğimizde solda ayarlamaları yapacağımız kısım, sağda ise henüz doldurulmamış ve döküm tablosu karşımıza gelecek. Sol panelde değişkenlerimiz ve veri tiplerini gösteren işaretler yer alıyor. Buradan değişkenlerimizi seçip Ok tuşuna basarak Variables (yeni analiz edeceğimiz değişken/ler) veya Split By (gruplama değişkenlerimiz) kısımlarına götürdüğümüz anda Döküm panelinde (sağ beyaz boşluk) sonuçlar görünmeye başlayacak.
Bu son derece şaşırtıcı şekilde hızla gerçekleşiyor. SPSS’de 70 yere basmadan ilerleyemeyen ben ilk seferinde bayağı etkilenmiş ve şaşırmıştım.
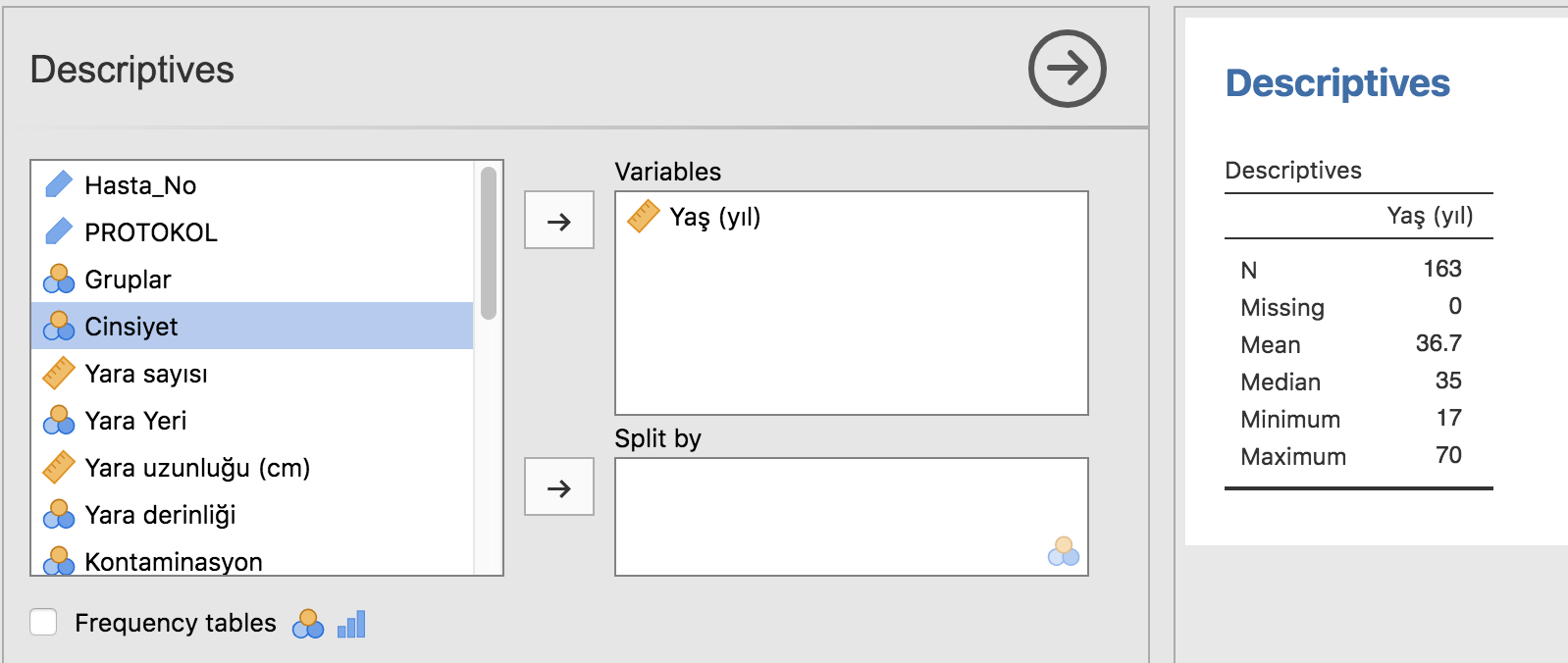
Eğer herhangi bir kategoriye göre bölmek istemezsek Split By kısmını boş bırakıyoruz. Tanımlayıcılar olarak rutinde N (vaka sayısı), Missing (eksik/boş vaka sayısı), Mean (ortalama), Median, Minimum ve Maximum değerleri sadece veriliyor. Bu elbette çok ama çok yetersiz. Hemen soldaki panellerin altında yer alan Statistics açılır menüsüne tıklayınca cevher ortaya çıkıyor. Rutinde işaretleyecekleriniz N, missing, mean, median, quartiles, Std. deviation ve Shapiro-Wilk olmalı. %95 Güven aralıkları bu panelden dökülemiyor (keşke olsaydı).


Seçenekleri işaretler işaretlemez Döküm panelinde sonuçlar görülmeye başlıyor.
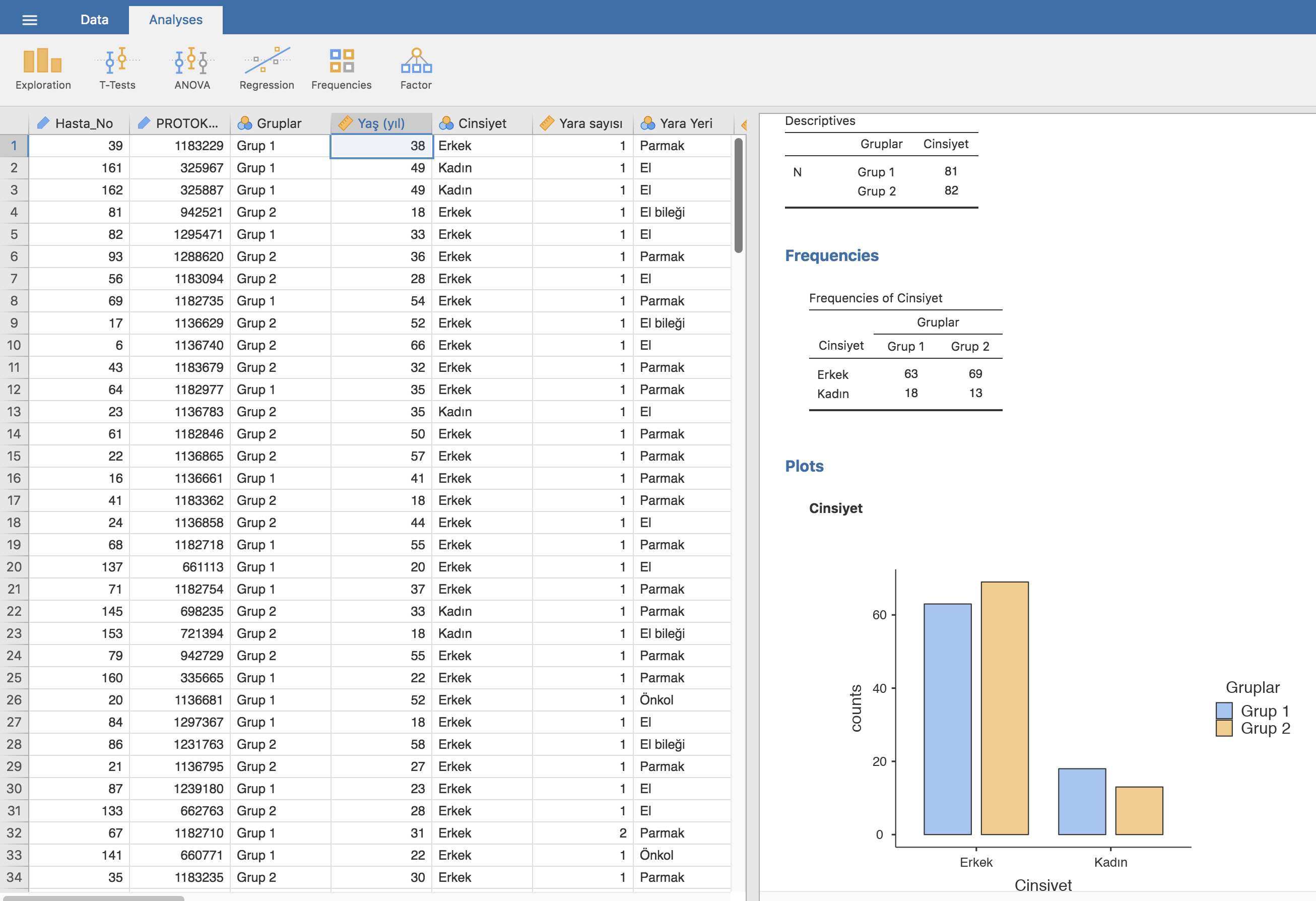
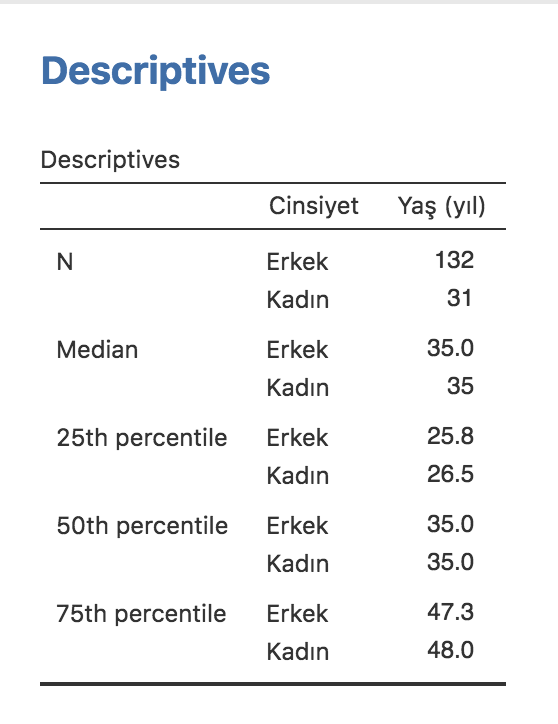
Üstteki örnekte önce sürekli bir değişkeni analiz paneline geçirdik: yaş. Bu değişkenin normal dağılmadığını (Shapiro-Wilk <0,001) bu sebeple de medyan ve interkuartil aralık bildirmemiz gerektiğini rahatça görebiliriz. Medyan değeri 35, interkuartil kenarlar da 25 ve 75. persentiller yani 26-48, ya da interkuartil aralık bunların farkı 22.
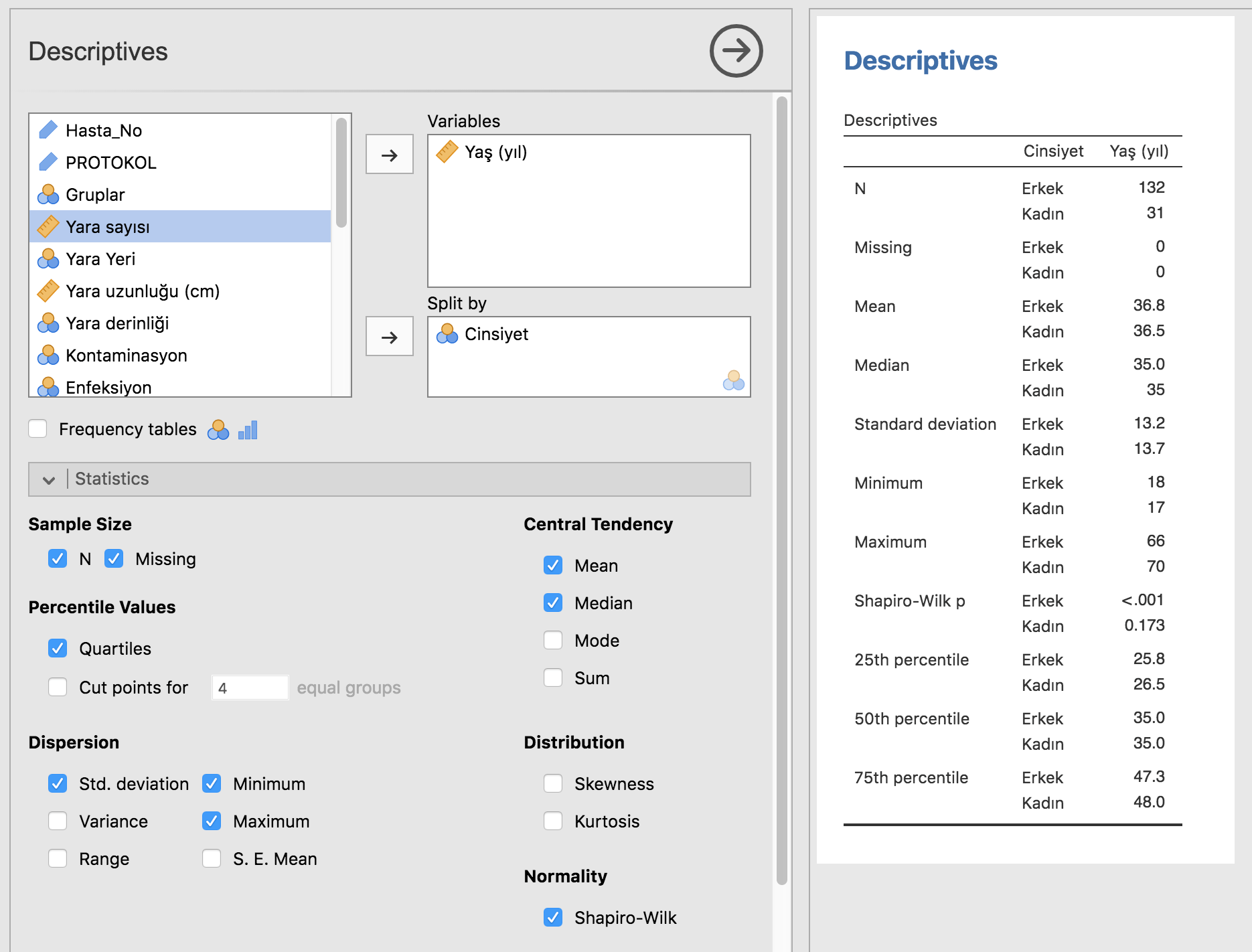
Cinsiyeti Split By paneline çeker çekmez yaş değişkeninin cinsiyet alt gruplarına göre dökümünü alıyoruz. Dökümdeki her bir elemanın üzerinde sağ tıklayarak tüm analizi (analysis), ya da sadece bir grafik ya da tabloyu (table) kopyalayabilir (Copy) ya da Save As diyerek PDF formatında kaydedebiliriz.
Tanımlayıcı grafiklerin hazırlanması
Jamovi’nin en kuvvetli yanlarından biri de olağanüstü hızda son derece yeterli ve baskı kalitesinde grafikler hazırlanmasını sağlaması. Tanımlayıcı grafikler için Statistics panelinin hemen altındaki Plots panelini tıklayarak bunu açıyoruz.
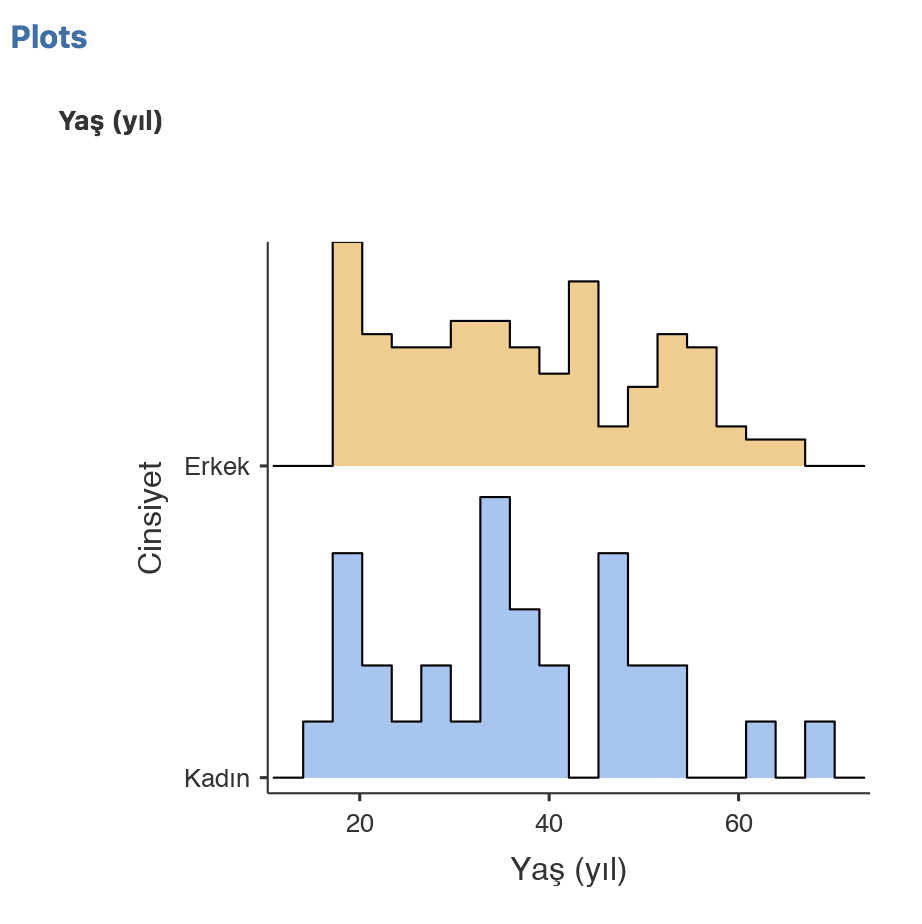
Histogram, Kutu-çizgi (box-plot) grafiği, Kutu (bar) grafiği, QQ plot çizdirebileceğimiz grafikler. Her birinin yanında hangi tip veri için uygun oldukları şekillerle belirtilmiş. Histogram kutusunu işaretler işaretlemez alttaki gibi yaşın cinsiyetlere göre bölünmüş histogramlarını elde ediyoruz. Veri yukarıdaki panellere nasıl girildiyse, hangi etiketler kullanıldıysa grafik de öyle çıkıyor. Üstünde düzeltme imkanı yok. Eğer hatalı bir değişken ismi ya da grup ismi yazmışsak değişken paneline dönüp düzeltmemiz yeterli! Grafik de otomatik olarak düzeliyor, hem de hepsi!
Histogram seçeneği seçili
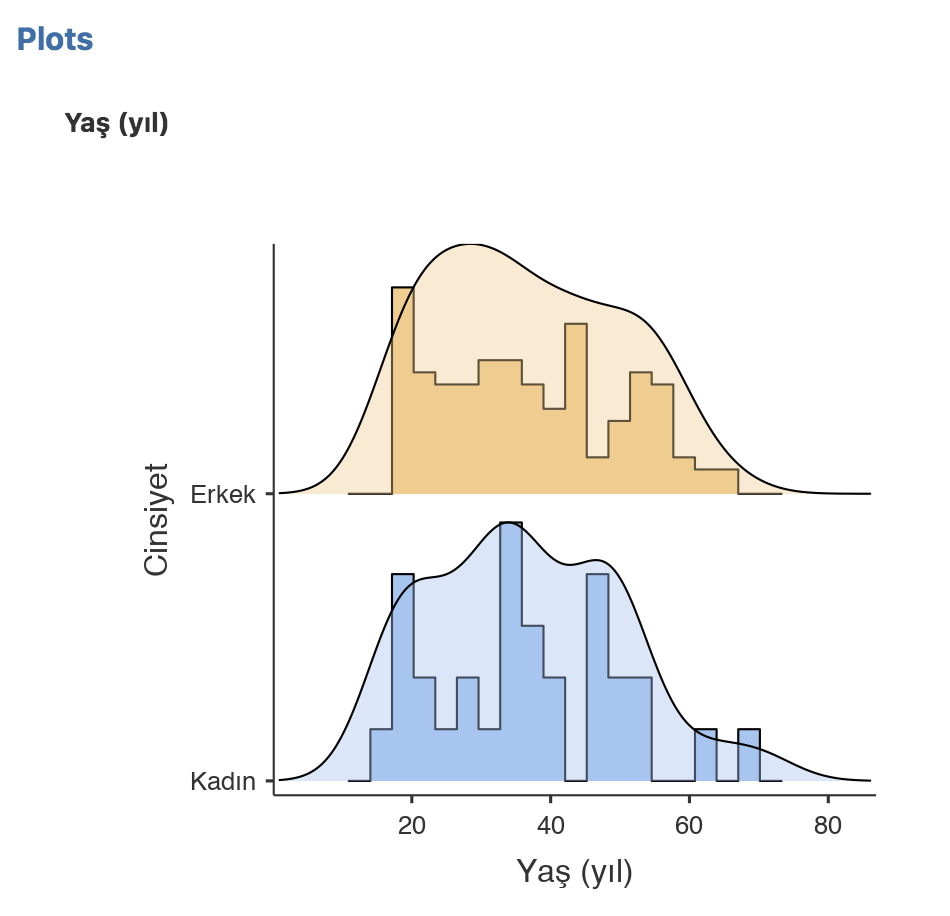
Histogram ve density seçenekleri seçili
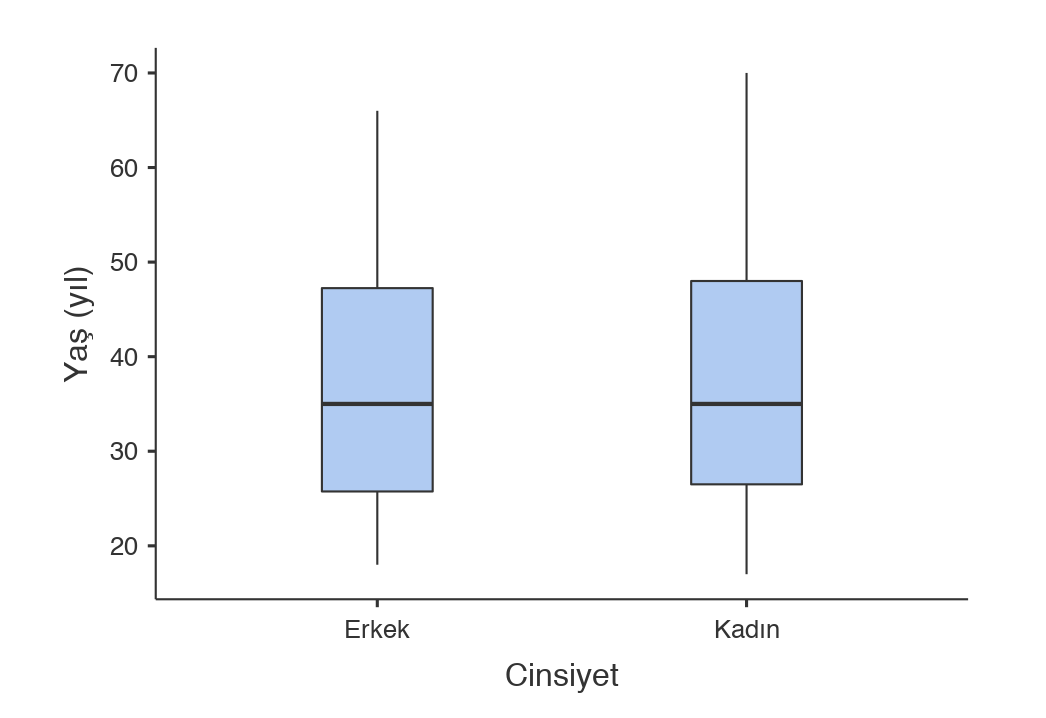
Box-plot grafiği
Eğer kategorik bir değişkeni incelemek istiyorsak bu sefer analiz paneline yaş yerine bunu koymalıyız: mesela cinsiyet. Split By kısmını temizlediğimizde Statistics ve Plots panellerini temizlemediğimizden yine aynı hesaplamaları anında bize döküyor. Ancak cinsiyet nominal bir değişken olduğundan (kadınların erkeklerden üstün olmadığını, yani sıralı değişken olmadığını saymak durumundayız) ortalama, medyan, kuartiller anlamsız birer veri. Bizim ilgilendiğimiz çalışma popülasyonunda kaçar tane kadın ve erkek olduğu ve bunun yüzdeleri. Bu sebeple hemen veri panellerinin altında, yanında ordinal ve nominal değişken şeklinin olduğu Frequency tables seçeneğini seçmemiz gerekiyor.
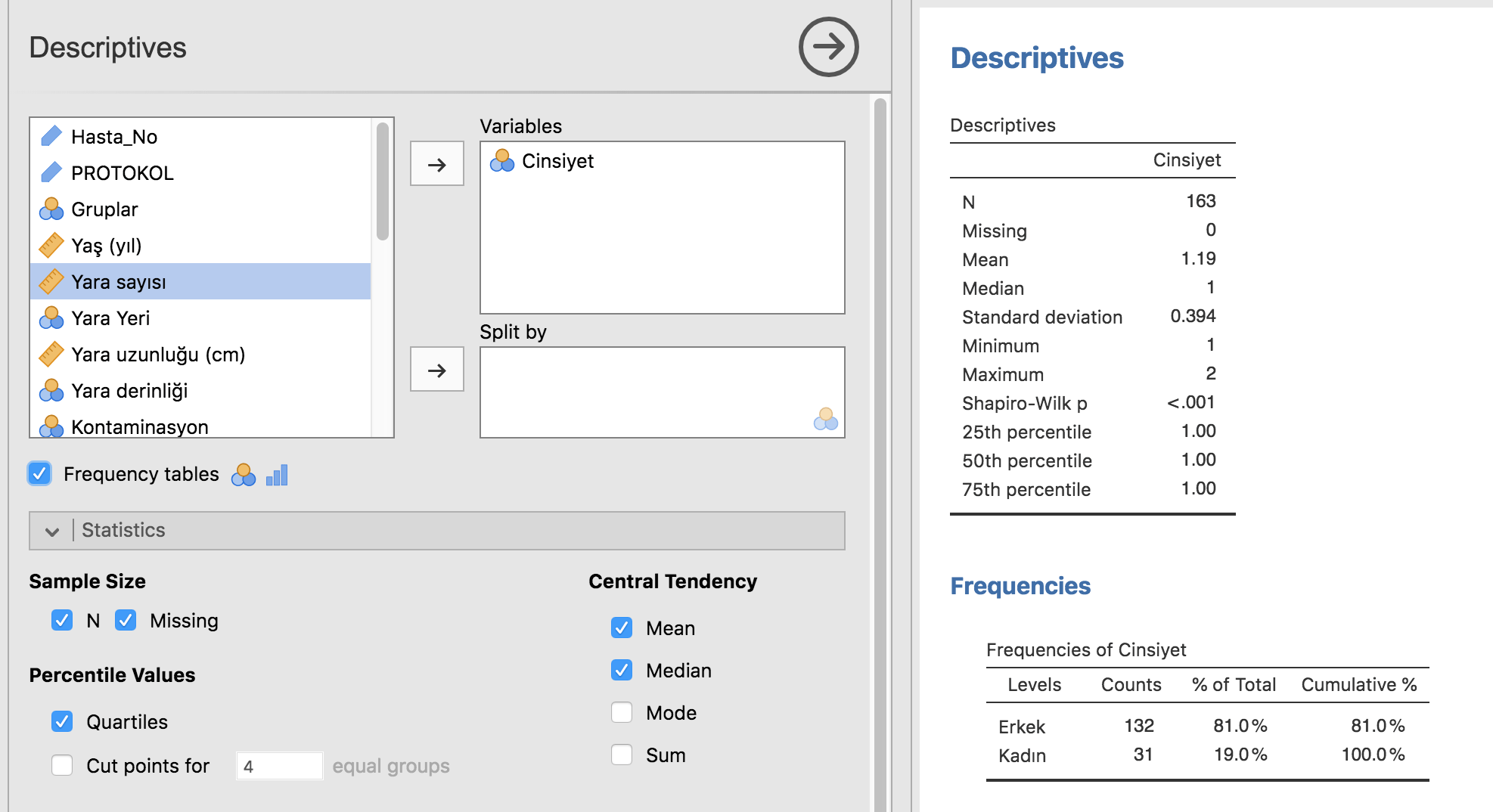
İşimize yaramayan seçenekleri kapatarak kalabalığı azaltabiliriz.
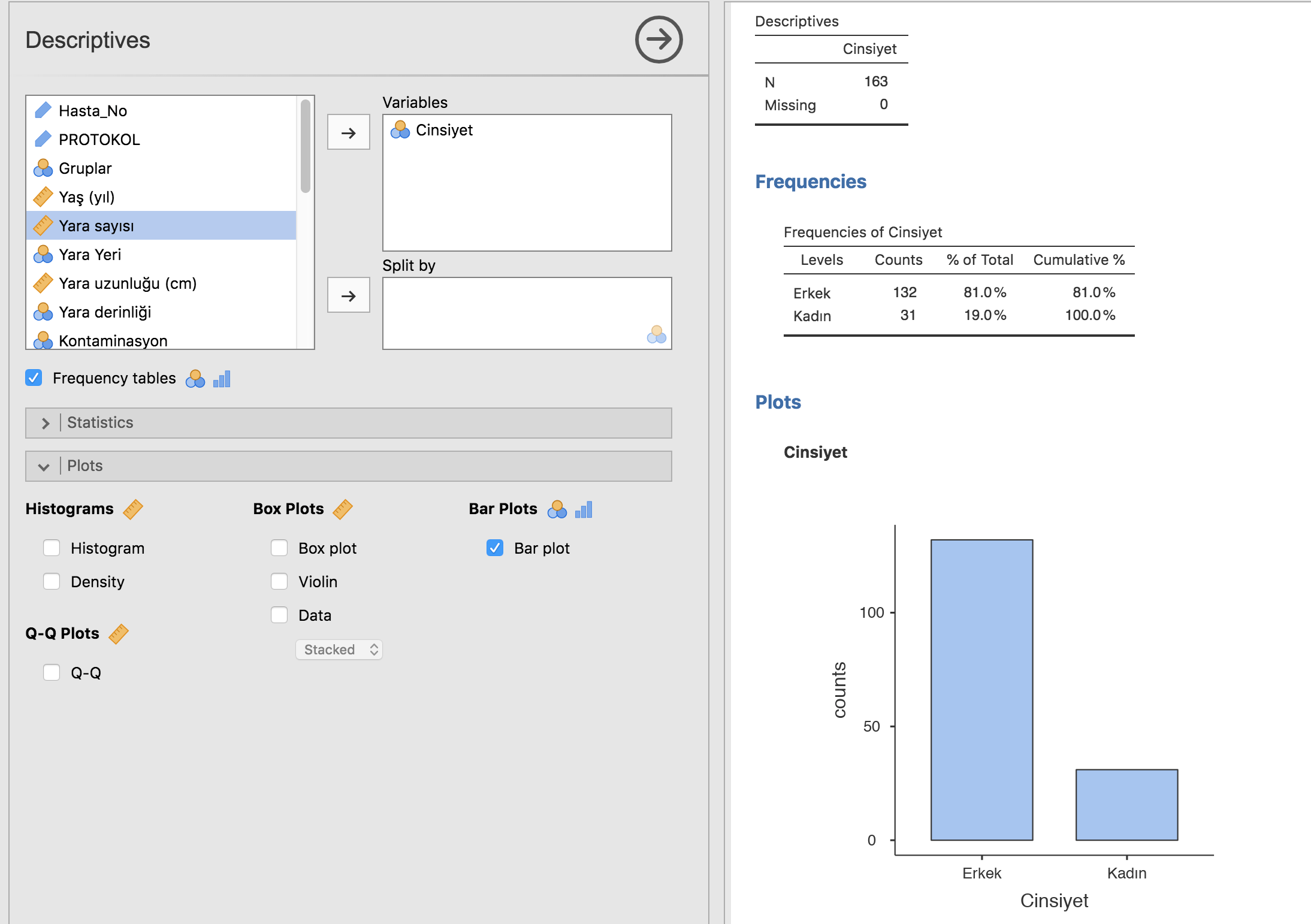
Kategorik değişkenleri de kategorik değişkenler altında analiz edebiliriz.
Yaptığımız döküm ve grafiklerden memnunsak ve başka analize geçeceksek sağ üstteki çember içindeki sağa ok seçeneğini seçiyor ve dökümü sağ panele kaydediyoruz.
Sürekli değişkenlerin 2 grup arasında karşılaştırılması
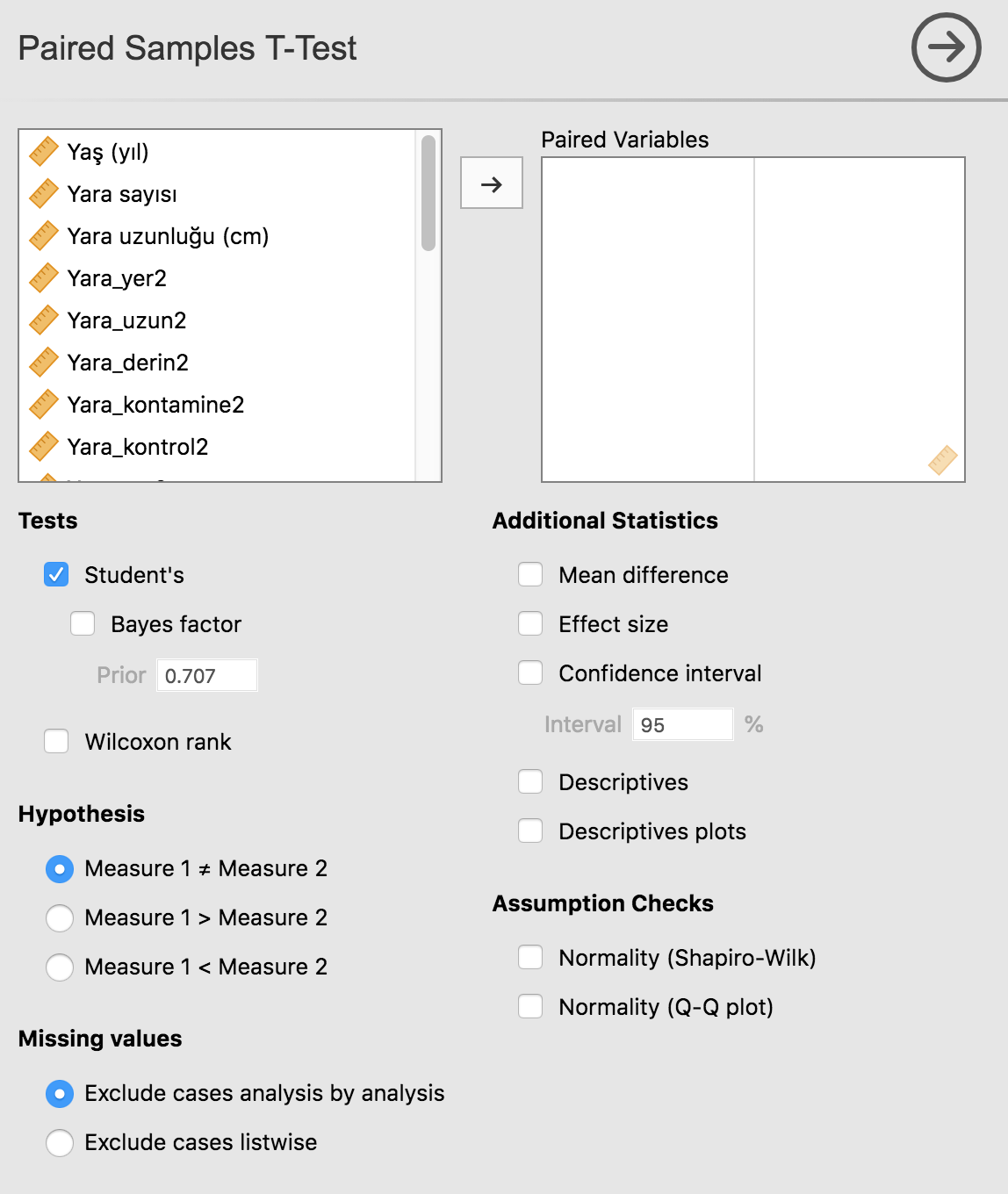
Bu amaçla T-tests seçeneği altındaki Independent samples t-test ve Paired samples t-test seçeneklerini kullanacağız.

Eğer sürekli değişken, karşılaştırılmak istendiği grupların her birinde normal dağılıyorsa sorun yok. Bağımsız gruplar varsa Independent samples t-test, ardışık ölçümler varsa Paired samples t-test kullanabiliriz.

Eğer sürekli değişken, karşılaştırılmak istendiği grupların herhangi birinde normal dağılmıyorsa parametrik olmayan testler kullanmamız gerekli.
Her iki testin de parametrik olmayan karşılıkları olan Mann-Whitney U ve Wilcoxon testleri kendi panellerinde birer kutucuk olarak var. Tıklamanız hesaplama için yeterli. Aynı panelde Assumption Checks altında normalite değerlendirmesi için Shapiro-Wilk testi ve QQ grafikleri de yer alıyor.
Hem de hatırlatma olması için burada test seçim kurallarını tekrarlayalım:
- Eğer Shapiro-Wilks ile dağılım normal (p>0,05), varyanslar da eşitse (Levene testi p>0,05) Student t,
- Eğer Shapiro-Wilks ile dağılım normal (p>0,05), varyanslar da eşit değilse (Levene testi p<0,05) Welch,
- Eğer Shapiro-Wilks ile dağılım normal değilse (p<0,05) Mann-Whitney U testi
Eğer dergi editörünün gözlerini yaşartmak istiyorsanız p değeri yeterli gelmeyecektir. Sizden ortalama ya da medyan fark, farkın güven aralıklarını vermeniz istenecektir. A grubu dergiler anlamlı bir fark varsa etki büyüklüğünü (effect size, burada Cohen’s d) de vermenizi isterler. Bunların hepsini SPSS’de yapmak ömrünüzü çürütebilir ama Jamovi ile çok kolay.
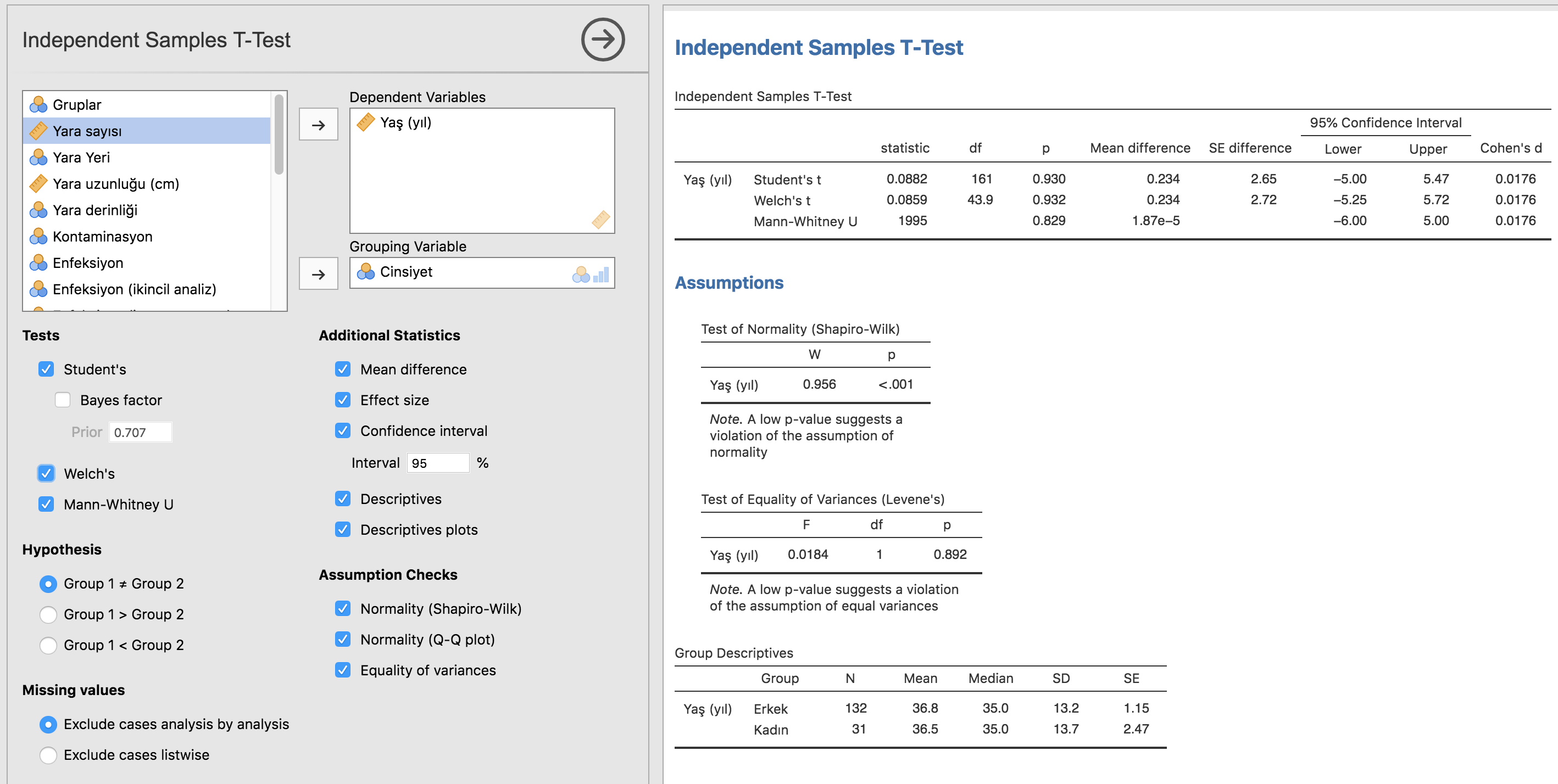
Örneğimizde yaş normal dağılmıyor (cinsiyet grupları arasında da). Bu sebeple medyan, interkuartil aralıklar ve Mann-Whitney U testi sonuçlarını bildireceğiz. Kuartiller sadece önceki tanımlayıcı analiz kısmından elde edilebiliyor. Hepsini bir araya getirdiğimizde:
- Erkeklerin ve kadınların medyan yaşları sırasıyla 35 yıl (İKA:25,8-47,3) ve 35 yıl (İKA:26,5-48,0) olup aralarında istatistiksel olarak anlamlı fark belirlenmemiştir (MWU p=0,829).
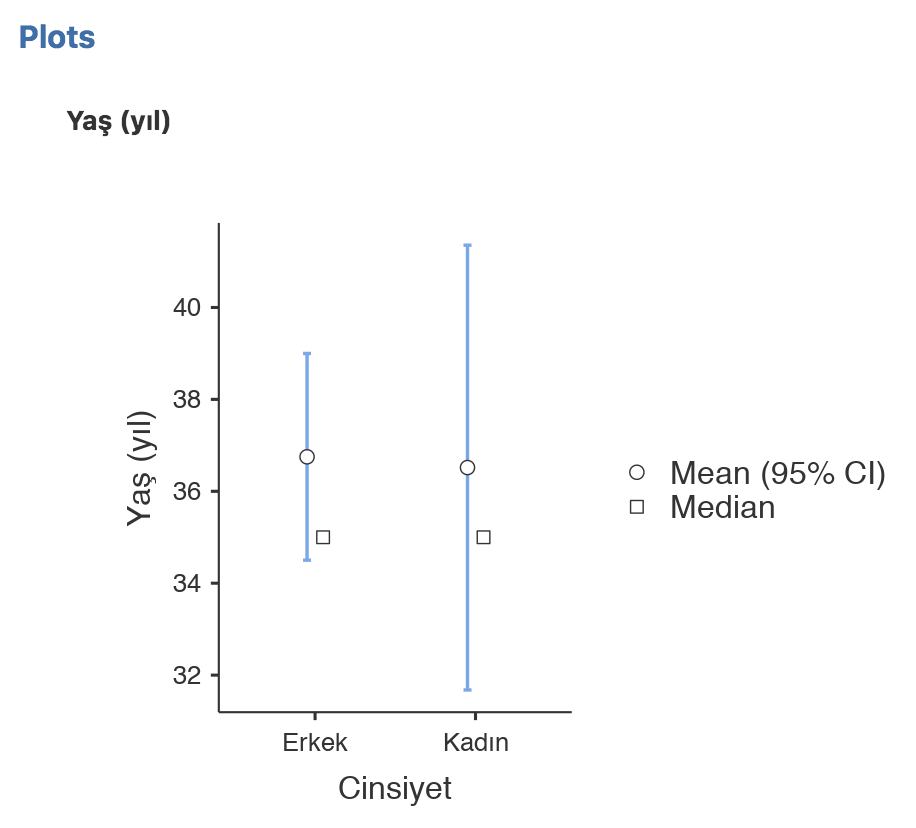
Bu panel otomatik olarak ortalama ve %95 güven aralıklarının olduğu hata grafiği de çiziyor. Bunun da örneğini hemen aşağıda görebilirsiniz. Ancak bu grafik üzerinde herhangi bir oynama yapamıyoruz.
Ki-kare testi
Çok gözlü tablolar için Frequencies >> contingency tables >> independent samples seçeneğini kullanacağız:

En temel şeklinde direk p değerini ve her hücreye düşen sayıları elde edebiliyoruz:
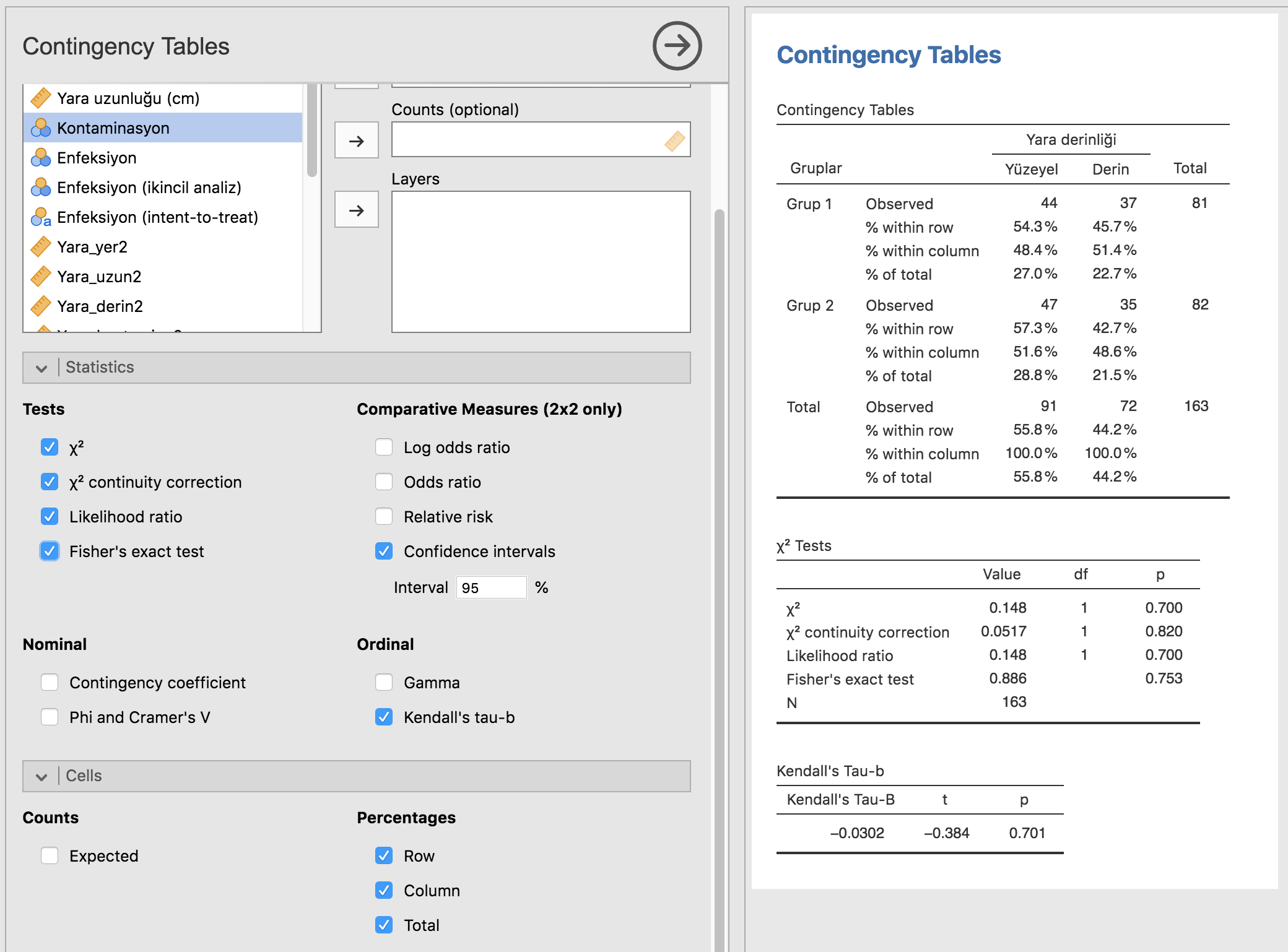
Ki-kare ile ilgili oldukça kapsamlı bir yazı yazmıştım. Bu seçeneklerin neler olduğunu oradan tekrar bakıp hatırlayabilirsiniz.
Kategorik değişkenler, Çok gözlü tablolar ve ki-kare hesabı
Tek yönlü ANOVA
ANOVA menüsü altından direk ulaşabiliriz. SPSS’e çok benzer seçenekleri mevcut:
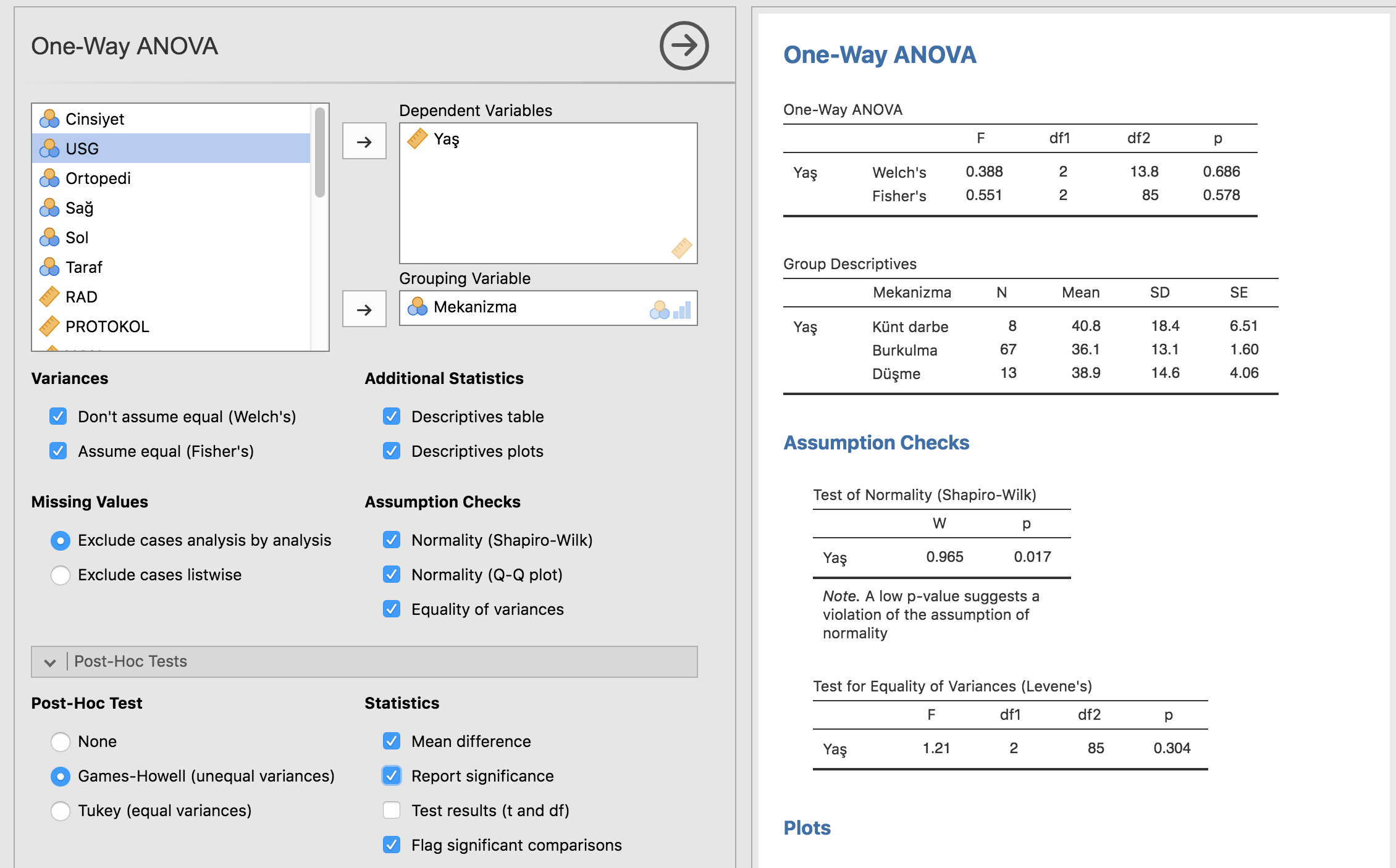
Testi yapmadan normallik ve varyansların denkliği ön şartlarına bakmak gerekse de hem SPSS hem de burada test hepsini döküyor, biz bakıp karar veriyoruz.
Yukarıdaki örnekte gerekli yerleri ben işaretledim. Buna göre Shapiro-Wilk’in p değeri <0,05 olduğundan normallik ihlal edilmiş. Ancak varyanslar denk (Levene p=0,304). Bu durumda Kruskal Wallis yapmak gerekse de elimizde bilgisayar olduğundan her ikisini de yapıp birbirine çok benzer sonuçlar varsa ANOVA’yı geçerli kabul etmek en doğrusu. İki değer birbirine yakında normalliğin ihlal edilmesi ANOVA testini bozmamış demektir.
Dolayısıyla varyanslar denk olduğundan Fisher’in ANOVA p değerini kabul ediyoruz: p=0,578 arada fark yok.
Hemen Kruskal-Wallis de yapıp normalliğin ihlali birşeyleri bozmuş mu görelim.
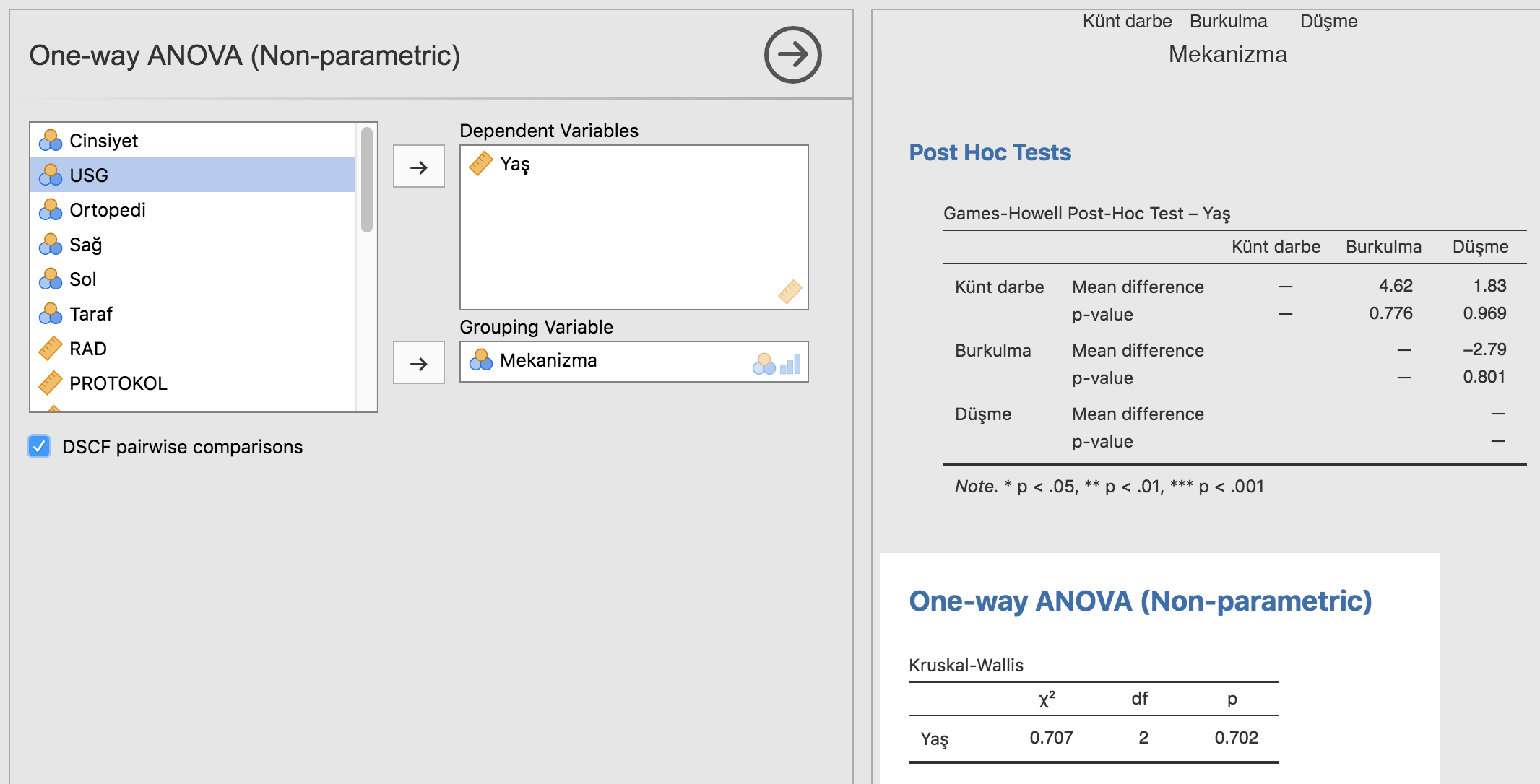
Kruskal-Wallis ekranı çok basit. Değişkenleri yerine koyduğumuzda hesaplanan p değeri 0,702.
Her ikisi de anlamsızlık seviyesinde ve hangisinin kullanıldığı sonucumuz açısından fark etmiyor.
Son Söz
Kabaca günlük pratikte kullanacağınız fonksiyonlar bunlar. Hepsi bedava, hepsi de gayet şık.
Ben tüm kursiyer ve okurlarımıza yasal olmayan yollara başvurmak yerine Jamovi kullanmalarını öneriyorum.
Cite as
AKOGLU, Haldun. (2018, September 27). Jamovi nasıl kullanılır? (Version v1). Zenodo. http://doi.org/10.5281/zenodo.1442523
Kaynaklar
[1] “The Popularity of Data Science Software,” Robert A. Muenchen, 19-Jun-2017. [Online]. Available: http://r4stats.com/articles/popularity/. [Accessed: 07-Jan-2019] [2] “ jamovi – Stats. Open. Now. ,” Jamovi, 19-Jun-2017. [Online]. Available: https://www.jamovi.org/. [Accessed: 07-Jan-2019] [3] “JASP – A Fresh Way to Do Statistics,” JASP – Free and User-Friendly Statistical Software, 19-Jun-2017. [Online]. Available: https://jasp-stats.org/. [Accessed: 07-Jan-2019]