

Çok gözlü tablolar iki kalitatif verinin birbiriyle karşılaştırılmasında kullandığımız karşılaştırma metodudur.
- Kalitatif veriler sınıflandırma belirtir. Bu tip veriyi tutan değişkenlere kategorik/gruplu/nominal değişkenler adı verilir
- Bu veri Cinsiyet, meslek, kurum, Well’s risk grubu, HT varlığı/yokluğu vb gibi bir veridir. Verideki sayı bir grubu/kategoriyi temsil eder.
- Örneğin, Cinsiyet değişkeninin değeri olan 0 ya da 1 sayılarının bir anlamı yoktur, aslında bu değer bir kategorinin kodudur. Cinsiyeti 1’den küçük, cinsiyetleri ortalaması 1,4 gibi bir değerlendirme anlamsızdır. Cinsiyet değerlerinin ortalaması, medyanı gibi merkezilik ölçütlerinin de bir anlamı yoktur.
- Her bir grup/kategori/faktör içindeki miktar sayılır. Örneğin, Cinsiyet değişkeninin erkek grubundaki kişi sayısına o grubun frekansı denir
- Meslek [doktor/hemşire/veri giriş] değişkeninin 3 grubu grubu/kategorisi/faktörü vardır
- Cinsiyet [erkek/kadın], sonlanım [yatış/taburcu], yatış [servis/YBÜ] değişkenlerinin 2 grubu/kategorisi/faktörü vardır. 2 grubu/kategorisi/faktörü olan değişkenlere Dikotom değişken de denilir.
- Sıralı olan kategorik/gruplu/nominal değişkenlere Ordinal değişken adı verilir. Öğretim durumu [ilk/orta/lise], kafa travması tipi [hafif/orta/ağır], GKS [3,4,5,…,14,15] hep ordinal verilerdir.
Kategorik verilerin SPSS’e girilmesi
SPSS’e kategorik değişkenler kaydedilirken her kategoriye bir numara verilir [0,1,2,3,4 vb]. Her deneğe ait veri ise satırlara eklenir. Sadece sayı kullanılır, isim ya da harf yazılmaz. Örneğin, cinsiyet değişkeninin alt grupları/kategorileri olan erkek ve kadın verisi yazılırken, her satırdaki denek için “Erkek” veya “Kadın” metinleri yazılmaz, “E” veya “K” harfleri kullanılmaz. Bunun yerine Erkek ve Kadın kategorilerine karşılık gelen, bir kenara not edilmiş, 0 ve 1 gibi sayılar kullanılır.

Variable view ekranında, o değişkene ait satırdaki Value labels seçeneği ile, o değişkenin kategorileri için tanımlanan numaraların hangi anlama geldiğini unutmamak için kaydedebilirsiniz. Ancak dosyanızı kaydederken (save data) .sav dosyası dışındaki kayıt sistemlerinin bu bilgiyi saklamadığını unutmayın.
Kategorik değişkenin bildirilmesi
Kategorik bir değişken bildirilirken frekansıyla ifade edilir. SPSS’de Analyze > Descriptive Statistics > Frequencies menüsünden ilgili değişkene ait döküm yapılır.
İlgili menüye girilince aşağıdaki seçim ekranı görülür. İstenen kategorik değişkenler değişken alanına alınır.
OK tuşuna basıldığından aşağıda listelenen dökümler alınır.
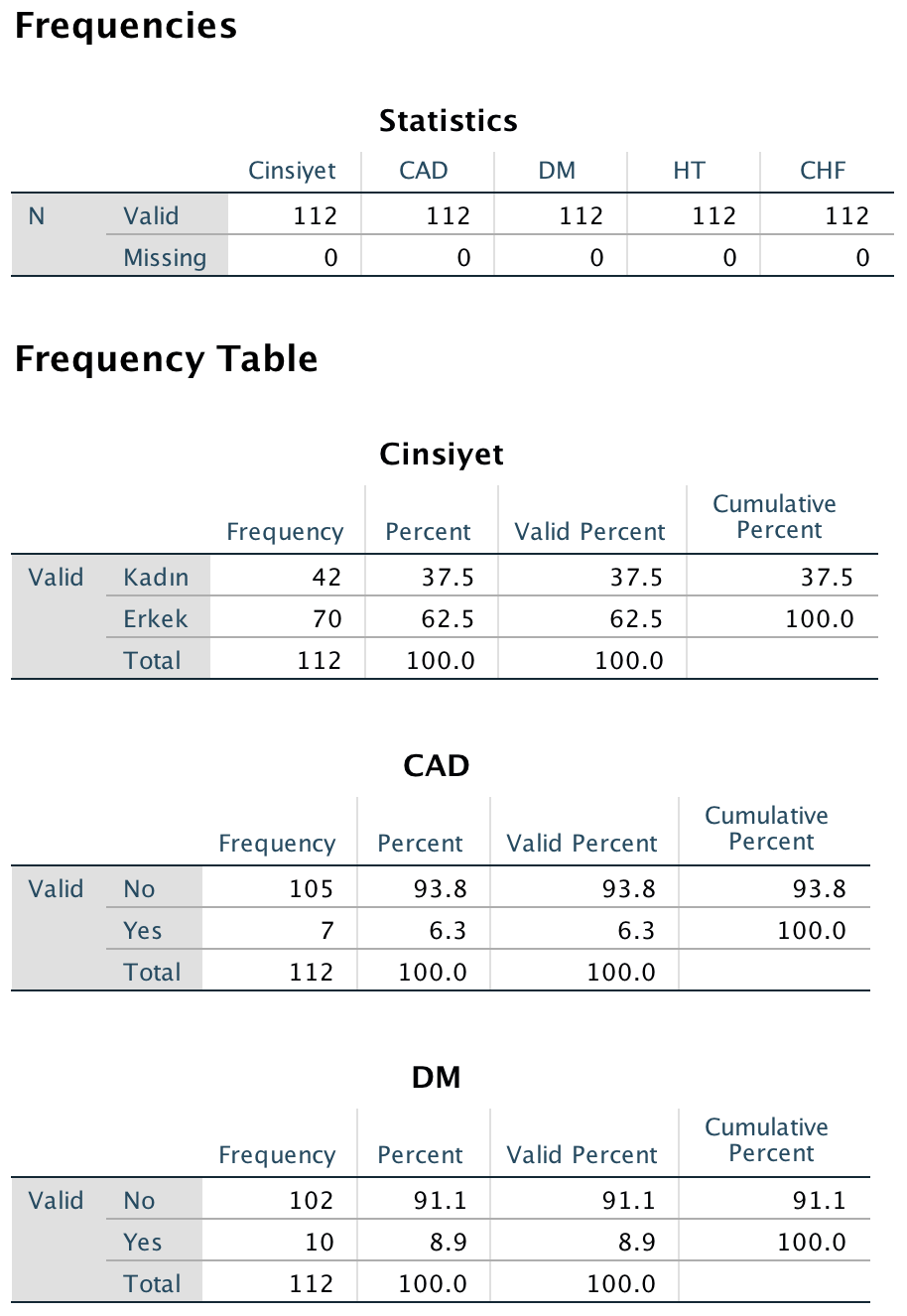
Kategorik değişken, hasta gruplarının temel özelliklerini içeriyorsa çalışmanın 1. Tablosunda gösterilmelidir.
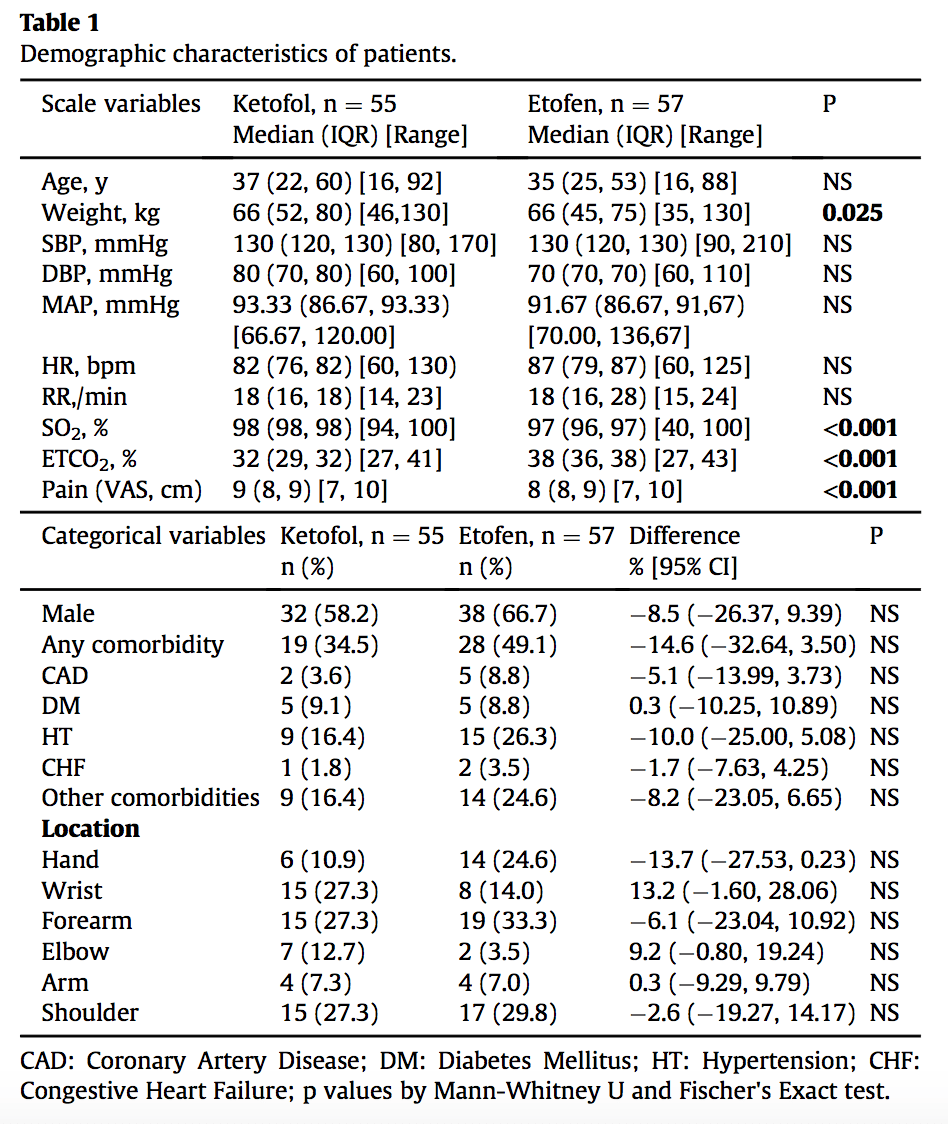
El ile Ki-kare hesabı
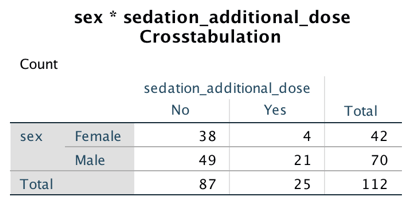
Çok gözlü tablolara Olasılık tabloları (contingency tables) ya da çapraz tablolar (crosstabs) da denilir.
- Sıfır hipotezi: iki değişken arasında ilişki ya da korelasyon yoktur
- Alternatif hipotez: iki değişken arasında ilişki ya da korelasyon vardır
Çapraz tablolar oluşturulurken etken, faktör ya da bağımsız değişken satıra; etkilenen, sonlanım ya da bağımlı değişken sütuna konulur.
Pearson’s chi-square (Pearson ki-kare).
- Klasik ki-kare testidir. Örneklem sayısından son derece etkilenir. Çok geniş örneklerde en ufak sapma bile anlamlıyken küçük örneklemlerde büyük sapmalar bile anlamsızdır.
- Örneklem boyutu küçüldükçe değeri düşer, bu yüzden de örneklem boyutuna bağlı İki ön şartı vardır:
- Çok gözlü tablonun her kutusunda en azından 1 vaka olmalıdır.
- Çok gözlü tablonun kutularından en fazla %20’sinde (yani 5’de 1’inde) 5’den az vaka olmalıdır.
- Yukarıdaki şartların sağlandığı her durumda, ve 2 x 2 dışındaki her tür tabloda Pearson chi-square hesaplanır
Fisher’s exact test (Fisher’in kesin testi)
- Pearson ki-kare’nin şüpheli sonuç verdiği küçük örneklem boyutlarında kullanılır.
- Kesin (exact) testlerden olup yaklaşık değil tam değerleri hesaplar
- Eskiden sadece 2 x 2 tablolar için hesaplanabilirken artık her türlü tabloda hesaplanabilmektedir. Eğer herhangi başka bir seçenek seçilmezse SPSS sadece 2 x 2 tablolarda hesaplama yapar. Eğer Exact ayarlarından Monte Carlo seçeneği aktif hale getirilirse m x n sayıda kutusu olan herhangi bir çokgözlü tablo için de hesaplama yapılır ve çıktıda bildirilir. Bu durumda p değerinin %95 güven aralığı da bildirilir.
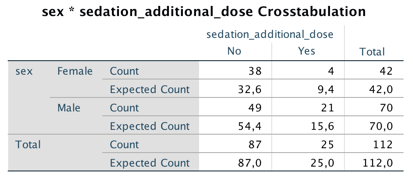
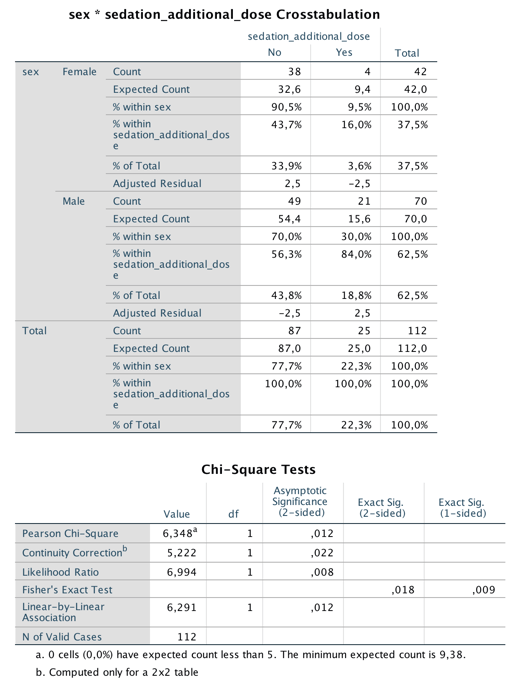
Eğer iki faktör/grup (satır) arasında fark yoksa, her sütunda satırlara karşılık gelen kutularda aynı oranda vaka olması gerekir. Örneğin, yukarıdaki tabloda 112 hastadan 42’si kadındır. O zaman sedasyon için ek doz (sütun) gereken (yes) 25 hastadan 42/112 kadarının (9,4) kadınlar arasından çıkmasını beklerim. Halbuki beklediğimizden daha az sayıda (4) vaka bu gruptan çıkmıştır. Alttaki tabloda bu şekilde hesaplanan beklenen (expected) değerler ile gözlenen (observed) değerler verilmiştir.
Ki-kare testinin sonucu son derece mantıklı bir hesaba dayanır. Üstteki tabloda görülen her bir kutuya düşen sayılarla, alttaki tabloda ifade edilen beklenen (expected) sayılar, yani beklenen ve gözlenen değerler arasındaki fark, ki-kare dağılımı ile karşılaştırılır.
[table id=34 /]
(Gözlenen – Beklenen)2 / Beklenen
Tüm kutular için yukarıdaki formüle göre sapma miktarları hesaplanır ve hepsi toplanır. Bu toplamda elde edilen sayı ki-kare değeridir.
[table id=35 /]
χ(chi)2= 0,89 + 3,10 + 0,54 + 1,87 = 6,4
Ki-kare değerinin bağımsızlık derecelerine göre en fazla kaç olması gerektiği bellidir. Bağımsızlık derecesi (df = degrees of freedom) ise şu şekilde hesaplanır:
df = (satır sayısı – 1) x (sütun sayısı – 1)
df = (2 – 1) x (2 – 1) = 1 x 1 = 1
Şimdi bulduğumuz ki-kare (χ2 ) değerini (6,4) aşağıdaki ki-kare (χ2 ) dağılım tablosuyla karşılaştıralım.
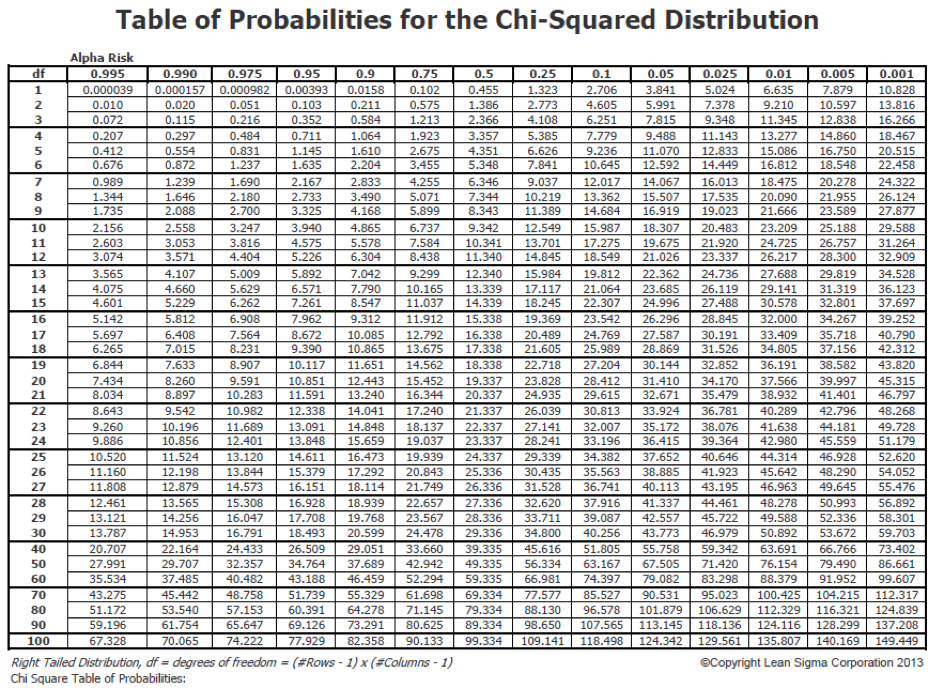
Tablomuzun df değeri 1 olan satırda 6,4 değeri 0,025 ile 0,01 olasılıkları arasında bir olasılığa tekabül etmektedir. Bu tablodaki ilişki ile ilgili olarak p değerinin 0,01 civarında olduğunu söyleyebiliriz.
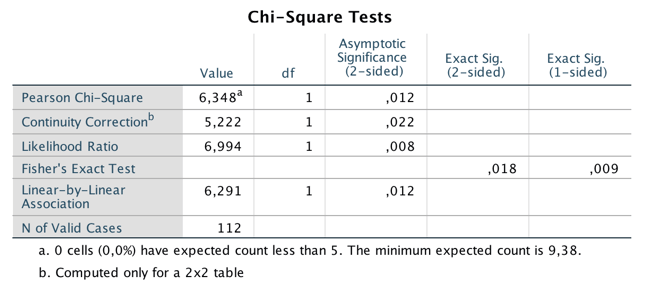
Aşağıda SPSS tarafından yapılan hesaplama gösterilmiştir. SPSS tarafından hesaplanan χ2 = 6,348 bizim hesaplarımızla aynıdır (Pearson chi-square değeri). P değeri de 0,012 olarak hesaplanmıştır (asymptotic significance).
Fisher’in kesin testi (Fisher’s exact test) adından da anlaşılacağı gibi daha “kesin” sonuç vermekte olup, SPSS, bu test ile p değerini 0,018 olarak hesaplamıştır (Exact sig.). Fisher testiyle hesapanan p değeri ki-kare ile hesaplanandan daha büyük yani anlamsızlık sınırına daha yakındır.
SPSS ile Ki-kare testi

Analyze > Descriptive Statistics > Crosstabs menüsüne girildiğinde aşağıdaki ekranla karşılaştırız. Bu ekranda çok gözlü tablonun satırlarında yer alacak değişkenleri row kısmına, sütünlarında yer alacak değişkenleri column kısmına yerleştirmeliyiz.
Genel kural olarak bağımsız değişkenler, prediktör faktörler, risk faktörleri, etkisini incelediğimiz girişimler ya da farklı tedavileri uyguladığımız grupları belirten değişkenler satırlara (row) yazılır. Bağımlı değişkenler, beklediğimiz etkiyi gösteren değişkenler, sonuçlar, sonlanımlar sütunlara yazılır. Ancak satır ya da sütuna hangisinin yazıldığı hesaplamaları değiştirmez. Eğer bu tip etki(sebep) – sonuç ilişkisi bulunmayan değişkenlerle ilgili ilişkiyi inceleyen analizler yapılacaksa istenildiği şekilde yazılmasında bir sakınca yoktur.
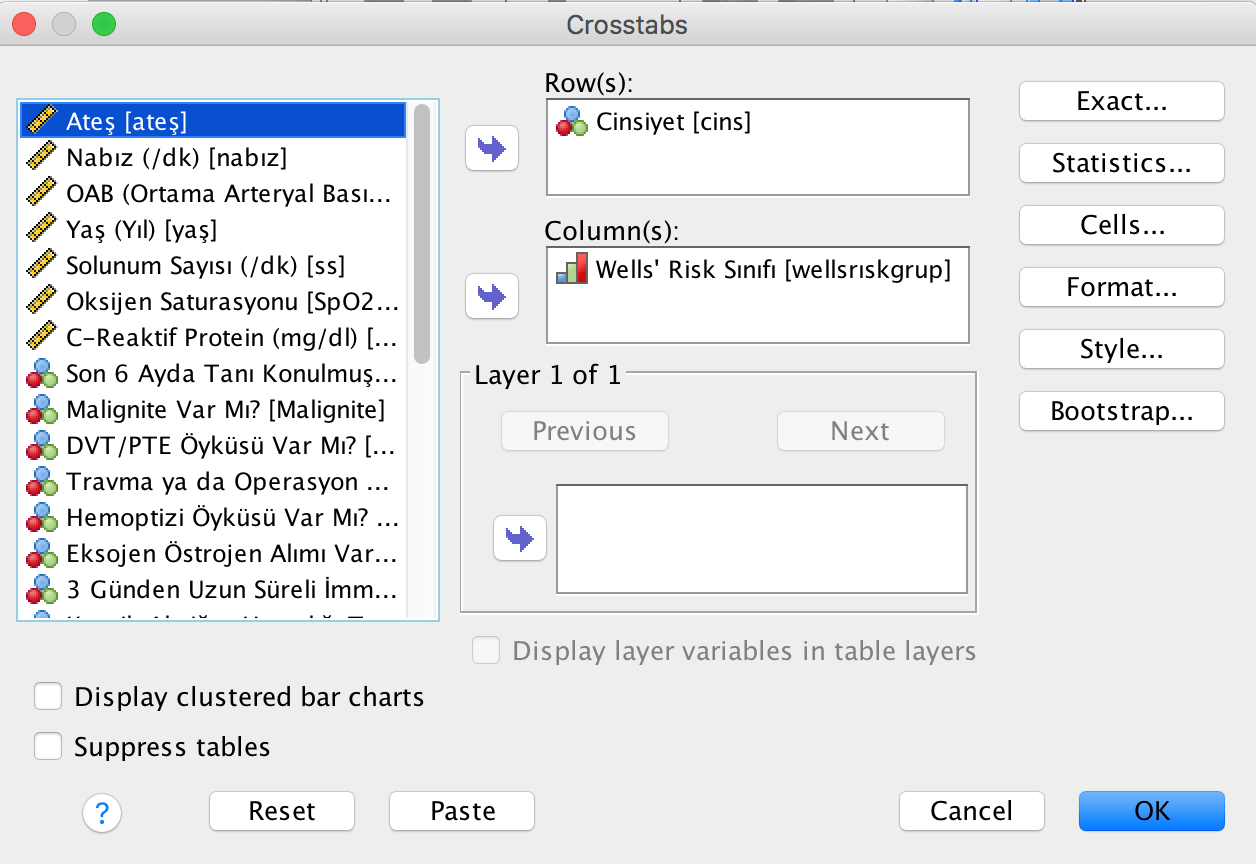
Sağ tarafta analize yardımcı olacak ayarlamaların yapıldığı Exact, Statistics, Cells, Format, Style ve Bootstrap seçenekleri mevcuttur.
Layer kısmına ise seçtiğimiz satır ve sütun değişkenlerini etkileyeceğini düşündüğümüz covariate adı verilen karıştırıcı değişkenler eklenir. Aynı anda birden fazla ki-kare testinin birarada yapılması ve karıştırıcı değişkenin etkisinin arındırılması için kullanılır. Statistics seçeneklerinde Cochran’s and Mantel-Haenszel statistics seçilerek bu katmanların etkisi aynı anda incelenebilir.
En basit şekilde hiçbir ayar yapılmadan alınan döküm aşağıdaki gibi olacaktır:

Hangi test seçilmeli?
- Verinin türüne göre, öncesi-sonrası gibi bir durum olmayan bağımsız değişkenler için çokgözlü tablolarda ki-kare (chi-square) seçilir.
- Bağımlı değişkenler için McNemar seçilir. Ya statistics ayarlarından, ya da Analyze >> Non-parametrik >> Legacy >> 2 related samples seçeneğinden McNemar seçilebilir.
- 3 ve daha fazla grubu olan ordinal değişkenler için Cochrane Q hesaplanır.
- Bu hesaplama için Analyze >> Non-parametrik >> Legacy >> K related samples seçeneğine gidilir.
Hangi ilişki katsayısı seçilmeli?
En temel olarak ki-kare analizinde analiz testlerinden biri ile ilişki büyüklüğünü gösteren katsayı testlerinden biri de seçilmelidir.
- 1 ya da 2 değişken nominalse > Cramer’s v
- Her ikisi de ordinalse > Kendall’s tau b veya c (satır, sütun sayısı eşitliğine göre)
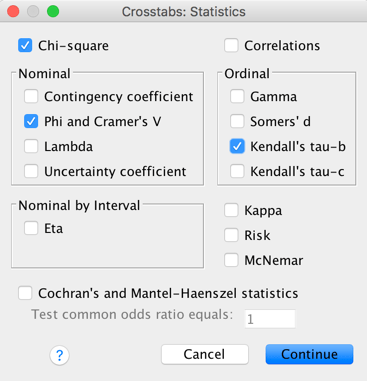
Dolayısıyla eğer ki-kare testi isteniyorsa statistics seçeneklerinden aşağıdakiler seçilir:
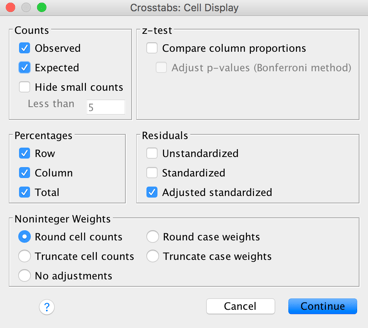
Cells seçeneklerinden de kısmında da aşağıdaki tabloda gösterilen kutuların seçilmesi yeterlidir.
OK tuşuna basılarak analiz tamamlanır ve çıktılar değerlendirilir.
Elde edilen analiz çıktısı yanda ve aşağıda verilmiştir. Tüm çıktıların anlamları ayarlarla ilgili kısımlarda açıklanmıştır.

Statistics ayarları
Chi-square (ki-kare).
Bu seçenek seçildiğinde 2 satır ve 2 sütundan oluşan 2 x 2 tablolarda:
- Pearson’s chi-square
- Continuity correction
- Likelihood ratio
- Fisher’s exact test
- Lineer-by-lineer association,
Daha fazla satır ve sütundan oluşan tablolarda ise:
- Pearson’s chi-square
- Likelihood ratio
- Lineer-by-lineer association,
sonuçları listelenecektir.
- Pearson’s chi-square (Pearson ki-kare).
- Klasik ki-kare testidir. Örneklem sayısından son derece etkilenir. Çok geniş örneklerde en ufak sapma bile anlamlıyken küçük örneklemlerde büyük sapmalar bile anlamsızdır.
- Örneklem boyutu küçüldükçe değeri düşer, bu yüzden de örneklem boyutuna bağlı İki ön şartı vardır:
- Her kutuda en azından 1 vaka olmalıdır.
- Kutulardan en fazla %20’sinde 5’den az vaka olmalıdır.
- Yukarıdaki şartların sağlandığı her durumda, ve 2 x 2 dışındaki her tür tabloda Pearson chi-square hesaplanır
- Fisher’s exact test (Fisher’in kesin testi)
- Pearson ki-kare’nin şüpheli sonuç verdiği küçük örneklem boyutlarında kullanılır.
- Kesin (exact) testlerden olup yaklaşık değil tam değerleri hesaplar
- Eskiden sadece 2 x 2 tablolar için hesaplanabilirken artık her türlü tabloda hesaplanabilmektedir. Eğer herhangi başka bir seçenek seçilmezse SPSS sadece 2 x 2 tablolarda hesaplama yapar. Eğer Exact ayarlarından Monte Carlo seçeneği aktif hale getirilirse m x n sayıda kutusu olan herhangi bir çokgözlü tablo için de hesaplama yapılır ve çıktıda bildirilir. Bu durumda p değerinin %95 güven aralığı da bildirilir.
- Continuity correction
- = Yates’ corrected chi-square (Yates’ düzeltmeli ki-kare)
- Sadece 2 x 2 tablolarda hesaplanır
- Beklenen ve gözlenen değer arasındaki farktan 0,5 çıkarır. Böylece hesaplanan ki-kare değeri küçülür, p değeri ise büyür.
- Özellikle küçük örneklemler fark yokken fark bulma ihtimalini azaltmak için İngiliz istatistikçi Yates tarafından önerilmiştir.
- En az 1 kutuda beklenen frekans 5’den küçük ise Fisher’s exact test yerine Yates’ corrected chi-square Buna rağmen özellikle küçük örneklemlerde gereğinden fazla düzeltme yaptığını, sıfır hipotezini reddetmesi gerekirken reddedemediğini ve böylece tip 2 hatayı arttırdığını savunanlar da vardır.
- Yukarıdaki örnekte SPSS tarafından hesaplanan c2 değerinin Pearson’daki 6,4 değerinden Yates düzeltmesi ile 5,2’ye düştüğünü, p değerinin de 0,012 yerine 0,022’ye yükseldiğini görüyoruz. Yates düzeltmesi ile Fisher’in kesin testi ile hesaplanan p değeri olan 0,018’den bile yüksek bir değer hesaplandığına dikkat ediniz.
- Linear-by-linear association
- = Mantel-Haenszel test of trend
- = Mantel-Haenszel test of Linear Association
- (Buradaki açıklamalar Martin Bland’ın York Üniversitesindeki ders notlarından alınmıştır – HA)
- En az biri ordinal olan iki değişken arasındaki ilişkiyi verir. Örneğin,
- bir önceki yılki değerlendirme notu ile sonraki yıl terfi etme arasındaki ilişi gibi.
- Verilen tedavi ile taburculuktan ölüme kadar değişen bir seri sonlanım gibi
- Bu tip durumlarda ordinal değişkenin sırası önemli olup giderek azalan ya da artan trendlerin de hesaba katılması önemlidir. SPSS bu amaçla 3 test yapabilir:
- Armitage chi-squared test for trend
- Mantel-Haenszel test of trend, ve
- Kendall’s rank correlation tau b
- Mantel-Haenszel test of trend, biz istesek de istemesek de SPSS tarafından Linear-by-linear association adı altında otomatik olarak ve her türlü tablo için bildirilmektedir. Satır ve sütun değişkenleri arasında lineer bir ilişki olup olmadığını test eder. Lineer dışında başka türlü bir ilişki olsa bile bunu değerlendirmediğinden bu konuda bilgi vermez.
- Lineer ilişkiden kasıt ise, ordinal kategorilere giderek artan sayılar verip (iyileşme düzeyi = 1, 2, 3, 4 vb), tedavi ya da grupları da numaralayıp (tedavi 1 =1, tedavi 2=2), bunu bir formül içine yerleştirebilmektir (iyileşme düzeyi = sabit x tedavi). Buradaki sabit sayıdan ziyade değişen kategoriler için sabitteki değişim hesaplanır ve buna da Mantel-Haenszel test of trend adı verilir.
- Ki-kare testi yapılamaz olsa bile (önşart sağlanmasa dahi) toplamda 30 vaka varsa Mantel-Haenszel test of trend yapılabilir ve anlamlı sonuçlar verir.
- Likelihood ratio (olabilirlik olasılığı) ki-kare.
- Geniş örneklemlerde Pearson ki-kare ile aynı sonucu verir. Özellikle az sayıda örneklemin olduğu tablolarda faydalıdır. LR’ler bildirilir.
Bu kısma kadar olan testlerle 2 değişken arasında bir ilişki ya da fark olup olmadığı sorusunun cevabı aranmıştır. Bundan sonraki seçenekler ise var olan ilişkinin büyüklüğünü göstermek için kullanılan testleri içerir.
Bir çapraz tablo değerlendirilirken bulunan değerlerin beklenen değerlerden sapmasının büyüklüğünü hesaplayıp, bu büyüklüğün görülme ihtimalini tablodan bulmuştuk. Bu ihtimal %5’den az ise 2 değişken arasında anlamlı ilişki var demiştik. Bu ilişkinin büyüklüğünü tanımlamak için değişkenin tipine göre aşağıdaki seçenekler kullanılır.
Tüm bu ilişki büyüklüğü belirten ölçütler için ortak bir tanımdan bahsedebiliriz. Buna Proportional Reduction in Error (PRE) adı verilir. Temel olarak, bağımsız değişkenin (etken, faktör) bilinmesi sayesinde bağımlı değişkenin (sonlanımın) ne düzeyde tahmin edilebileceğinin ölçütüdür.
Correlations (korelasyonlar).
- Hem satır hem de sütunlarında sıralı (ordinal) değişkenler olan tablolarda bu seçenek kullanılır.
- Spearman’ın korelasyon katsayısı olan ro’nun (Spearman’s correlation coefficient, rho) raporlanmasını sağlar. Spearman’ın ro’su sıralı (ordinal) düzenlerin arasındaki ilişkinin büyüklüğünü ölçer.
- Her iki değişken de kantitatif ise Pearson korelasyon katsayısı olan r’yi bildirir (Pearson’s correlation coefficient,r). r değişkenler arasındaki lineer ilişkinin büyüklüğünü bildiren bir ölçüttür.
Nominal.
Kendi içinde bir sırası olmayan kategorik değişkenler için bu seçenekler seçilebilir.
- Lambda (l) ve Goodman ve Kruskal’s tau (t)
- Simetrik ve asimetrik Lambda ile Goodman ve Kruskal’s tau (t) katsayılarını verir.
- Proportional Reduction in Error (PRE) değerini verir.
- 1 değeri bağımsız değişkenin bağımlı değişkeni mükemmel şekilde öngörebildiğini gösterir. 0 değeri bağımsız değişkenin değerinden bağımlı değişkenin öngörülme şansı olmadığını belirtir.
- SPSS hangi değişken bağımlı hangisi bağımsız bilemeyeceğinden ikisini de hesaplar. Simetrik olan ölçütün bizim için çok bir anlamı yoktur.
- Asimetriklerden doğru sırada olan seçilmelidir.
- Lambda (l) oldukça konservatif bir ölçüttür.
- Goodman ve Kruskal’s tau (t) lambda’dan daha iyi olsa da onlar da konservatiftir.
- Lambda (l) ve Goodman ve Kruskal’s tau (t)’nun bu eksiklikleri nedeniyle ki-kareden türetilmiş Phi, Cramer’s V ve contingency coefficient katsayıları da kullanılmaktadır. Ancak ki-kareden türetilen aşağıdaki katsayılar PRE değerini veremez.
- Contingency coefficient
- Ki-kare testine bağlı olarak hesaplanır. 0 ile 1 arasında değişir. 0, satır ve sütun değişkenleri arasında hiç ilişki olmadığını, 1 ise tam bir ilişki olduğunu gösterir.
- Maksimum alabileceği değer tablonun satır ve sütun sayısından etkilenir. Bu yüzden farklı satır ve sütun sayılarına sahip farklı tabloları birbiriyle karşılaştırmada değersizdir.
- Phi (j) ve Cramér’s n
- Phi (j), ki-kare istatistik değerini örneklem boyutuna bölüp kare-kökünü alarak hesaplanır.
- Cramer’s n, 2×2 tablolarda hesaplanan phi (j) katsayısıdır.
- Uncertainty coefficient
- Lambda’ya benzer şekilde aynı ölçütü bildirir.
Ordinal.
Hem satır hem de sütunda sıralı (ordinal) değişkenler varsa
- Gamma (g)
- Lambda’nın ordinal değişkenler için olan versiyonudur
- Her 2 değişken de ordinal olmalıdır.
- -1 ile +1 arasında değişir. 1’e (eksi ya da artı) yakın olan değerler güçlü ilişki lehineyken 0’a yakın değerler ilişki yokluğunu gösterir.
- Ardışık giden değişkenler için, örneğin bir vaka değişkenlerin birinde başka bir vakadan büyükse, diğer değişken için de diğer vakadan büyük olmalıdır. Böyle vakalar konkordan (C), bu kurala uymayanlar diskordan (D) vakalardır. Formülü şu şekildedir:
- g = (C – D) / (C + D)
- Bu formüle göre tüm vakalar konkordan ise g tam +1 olur. Ordinal uyumun her iki değişkende mükemmel olduğunu gösterir.
- Formüle göre hesaplanan g değeri, işaretinden bağımsız olarak, PRE değerini gösterir.
- Lambda gibi bazı kısıtlılıkları vardır. En önemlisi de eşitlik durumlarını yok saymasıdır. Bu eşitlik durumunu da hesaba katan ise Kendall’s tau katsayısıdır.
- Kendall’s tau-b.
- Satır ve sütun sayısı eşitse geçerlidir.
- Ordinal ya da sıralı (ranked) değişkenler için eşit olma durumunu da hesaba katan non-parametrik bir ilişki ölçütüdür.
- Hesaplanan katsayının işareti (eksi ya da artı) ilişkinin de yönünü belirtir.
- Katsayının büyüklüğü ilişkinin büyüklüğünü gösterir. -1 ile +1 arasında değişir. Ancak tam -1 ya da +1 sadece tam kare şeklindeki tablolarda görülür.
- Kendall’s tau-c.
- Satır ve sütun sayısı eşit değilse kullanılır.
- Somers’ d.
- Kendall’s tau’ya göre daha nadir kullanılır.
- 2 ordinal değişken arasında satır kategorilerine göre kolon kategorisini öngörme gücünü gösterir.
- -1 ile +1 arasında değişir. 1’e (eksi ya da artı) yakın olan değerler güçlü ilişki lehineyken 0’a yakın değerler ilişki yokluğunu gösterir.
| İlişkinin Gücü | Lambda, Gamma, Pearson’s r |
| Yok | 0.00 |
| Zayıf | + 0.01 – 0.09 |
| Orta | + 0.10 – 0.29 |
| Yüksek | + 0.30 – 0.99 |
| Mükemmel | + 1.00 |
Nominal by Interval.
- Değişkenlerden biri kategorik diğeri kantitatif ise Eta seçilmelidir.
- 0 ile 1 arasında değişir.
- Özellikle bağımsız değişkenin az sayıda kategoriden oluştuğu (cinsiyet: erkek / kadın), bağımlı değişkenin ise interval bir sürekli değişken olduğu durumda (gelir miktarı) Eta çok uygun bir ilişki gücü göstericisidir.
- SPSS 2 farklı Eta değeri hesaplar: biri satır değişkenini interval olarak kabul eder, diğeri de sütun değişkenini. Doğru şekilde kullanılması gereklidir.
Yukarıda belirtilen ilişki katsayıları dışında bu ayarlar menüsünden seçilebilen birkaç test daha vardır:
Kappa.
- Aynı objeyi numaralandıran/skorlayan/ölçen 2 değerlendirici arasındaki uyumu (agreement) ölçer, Cohen’s kappa diye bilinir.
- 1 mükemmel uyum, 0 uyumsuzluk (şans faktöründen farklı değil) anlamına gelir.
- Hem satır hem de sütun değişkeninin birebir aynı isimde ve sayıda kategorilere sahip olması gereklidir.
- Bir değişkende gözlenen ama diğer değişkende olmayan tüm değerlerin olduğu vakalar hesap dışına çıkarılır.
Risk.
- 2 x 2 tablolarda bir faktörün varlığı ile (satır) bir sonucun görülmesi (sütun) arasındaki ilişkiyi gösterir.
- Riskin güven aralığı 1 değerini içeriyorsa faktör ile sonuç arasında ilişki var denilemez.
- Faktörün sıklığı düşük ise risk yerine odds oranı kullanılabilir.
McNemar.
- 2 x 2 tabloda 2 dikotom değişken arasındaki ilişkiyi non-parametrik şekilde test eder.
- Özellikle yanıtlardaki değişim gibi bağımlı değişkenlerdeki farkı ve değişimi test etmek için kullanılır.
- Öncesi-sonrası dizaynlarda özellikle tercih edilir.
- 2×2’den büyük tablolarda bu seçenek seçilirse McNemar yerine McNemar-Bowker simetri testi (test of symmetry)
- Bu ayar menüsü dışında SPSS’de 2 farklı yerden daha McNemar testi hesaplanabilir
Cochran’s and Mantel-Haenszel statistics.
- Eğer iki değişken arasındaki ilişki araştırılırken diğer başka değişkenler açısından etkinin standardize edilmesi gerekiyorsa tabakalar (layers) halinde birden fazla ki-kare testinin aynı anda yapılması esasına dayanan Cochran’s and Mantel-Haenszel statistics yapılmalıdır.
- Örneğin, bir vaka-kontrol çalışmasında, satırlar vaka ve kontrol grupları, kolonlar da sonlanım (öldü, yaşıyor) ise, yani her ikisi de kategorik değişken ise, ve sonucu etkileyebileceği düşünülen diğer faktörler açısından standardizasyon yapmak istiyorsak (cinsiyet, meslek vb), bu istatistiği kullanırız.
Cells ayar menüsü
Bu kısımda tablonun içindeki kutularda yer almasını istediğimiz değerleri seçiyoruz.
Counts
- Gözlenen (observed) ve Beklenen (expected) değerleri için ilgili kutular işaretlenir.
Percentages
- Satır (row) ve sütun (column) yüzdeleri için ilgili kutular işaretlenir.
Residuals
- Gözlenen ve beklenen değerler arasındaki fark ve bunlarla ilgili hesapları içerir
- Unstandardized = Gözlenen – Beklenen. Pozitif olması, olmasını beklediğimizden belirtilen sayı kadar fazla vaka olduğunu belirtir.
- Standardized. Ortalamaları 0 ve standart sapması 1 olacak şekilde yeniden hesaplanır. Kutuların sapmaları birbirleri ile oransal olarak karşılaştırılabilir.
- Adjusted standardized. Ortalamaları 0 ve standart sapması 1 olacak şekilde yeniden hesaplanan rezidülerin kaç standart sapma birimine denk geldiği belirtilir. Kutulardaki sapma miktarı farklı tablolardaki verilerle karşılaştırılabilir. -2 ya da +2’den büyük kutular özellikle anlamlı farklılık içeren kutulardır.
Z-Testi
- Compare columns ve Adjust p-values (bonferroni) seçenekleri seçili olduğu anda her kolon kendi içinde karşılaştırılır. Birbirine benzer kutular aynı harf ile işaretlenir. Böylece farkın kaynaklandığı kutular belirlenir. P değeri de çoklu karşılaştırma yapılması sebebiyle bonferroni düzeltmesi ile (anlamlılık eşiği olan p değerinin karşılaştırma sayısına bölünmesi) düzeltilir.