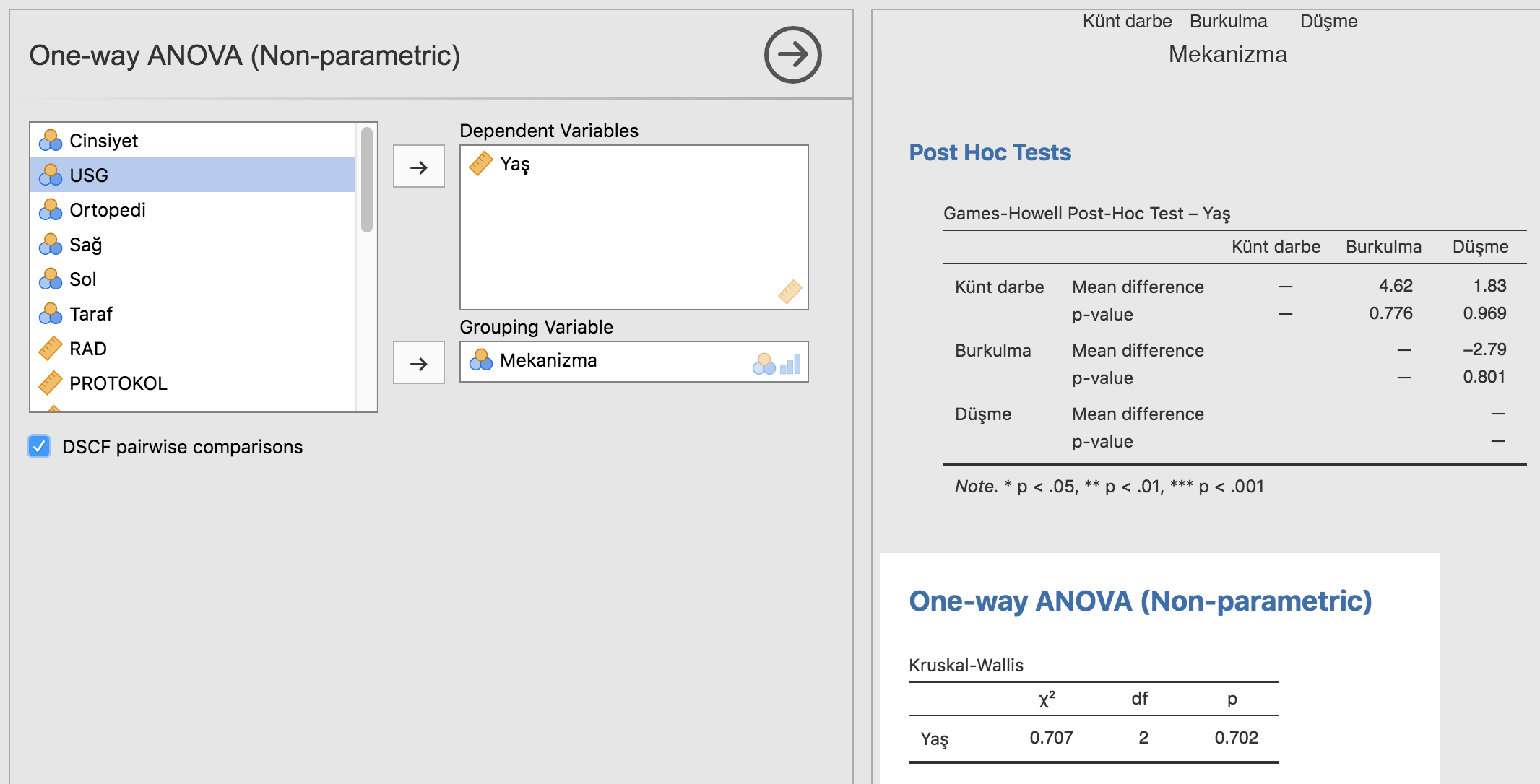
Bir klinik araştırmanın metodolojisi ve taksonomisi
Tıpkı biyolojik taksonomide olduğu gibi çoğu çalışmayı kategorize etmek için benzer bir hiyerarşiden yararlanabiliriz (Şekil 1) [1,2].

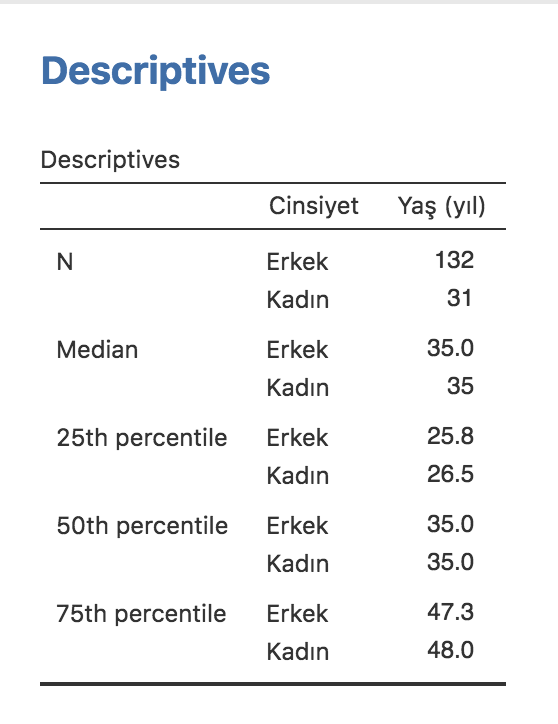
Bir çalışmanın anatomisi, yani metodu, o çalışmanın neyi bildirip neyi bildiremeyeceğini bize anlatır. Biz okuyucular için en önemli handikaplardan biri de yazarların her zaman çalışmanın tipini belirtmemesi ve bizim çıkarım sağlamamıza olanak verecek ayrıntılardan bahsetmemeleridir. Daha kötüsü, yazarlar bazen çalışmanın tipini yanlış belirtebilir. Örneğin, randomize olmayan kontrollü çalışmaları, randomize kontrollü olarak; eşzamanlı olmayan kohort çalışmaları da vaka-kontrol çalışması olarak belirtmek sık karşılaşılan hatalardandır. Vaka-kontrol kelimesinin de uygunsuz biçimde her kontrol grubu olan çalışmada kullanıldığını görmekteyiz. Biyolojinin ana grupları olan hayvanlar ve bitkiler gibi, klinik araştırmaların da ana grupları deneysel ve gözl emsel çalışmalardır (Şekil 2).[3]

| Bu noktada kohort kelimesinin biraz üstünde durmakta fayda var. Kohort kelimesi tıbbi değil askeri bir terimdir. Doğu Roma İmparatorluğu’nda 300 ila 600 kişilik birliklere kohort adı verilirdi. 10 kohort bir lejyonu oluştururdu. Kohort; ortak bir tecrübe, maruziyet ya da durumu paylaşan insanlar anlamında kullanılır. Mesela doğum kohortu aynı yıl doğanları, sigara içenler kohortu sigara içme yönünden ortaklığı olan bir grubu belirtir. Bu açıdan insanların birim ölçek olduğu tüm çalışmalarda örneklenmiş insan toplulukları aslında birer kohorttur. |
Gözlemsel çalışmalar
Bu çalışma dizaynı ilevar olan bir durumun farklı yönleri gözlenir. Anket ya da vaka sunumunu buna örnek verebiliriz. Elde ettiğimiz veriler yoluyla gözlediğimiz durumla beraber bulunan farklı yönleri sayısal biçimde açıklamaya çalışırız.
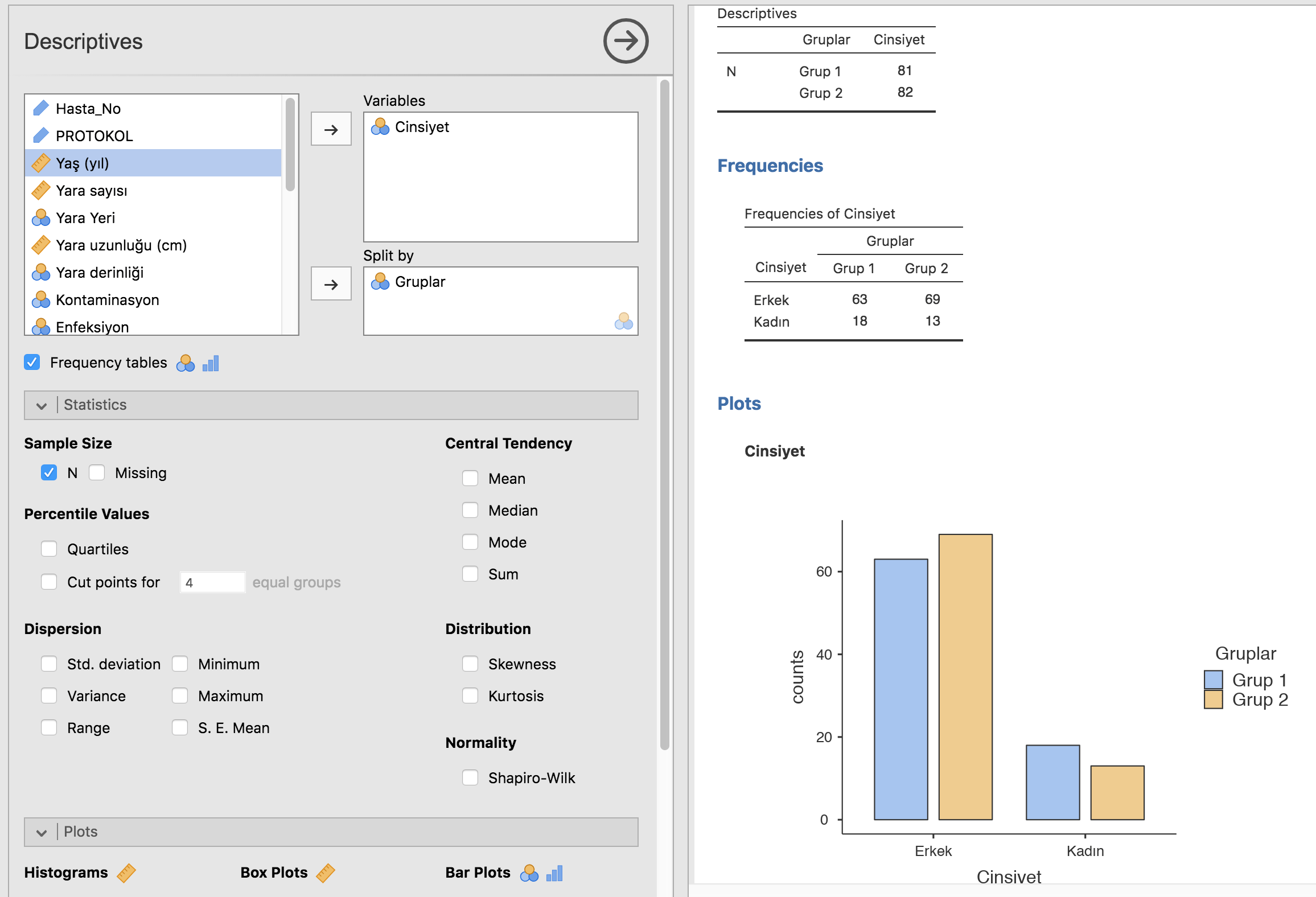
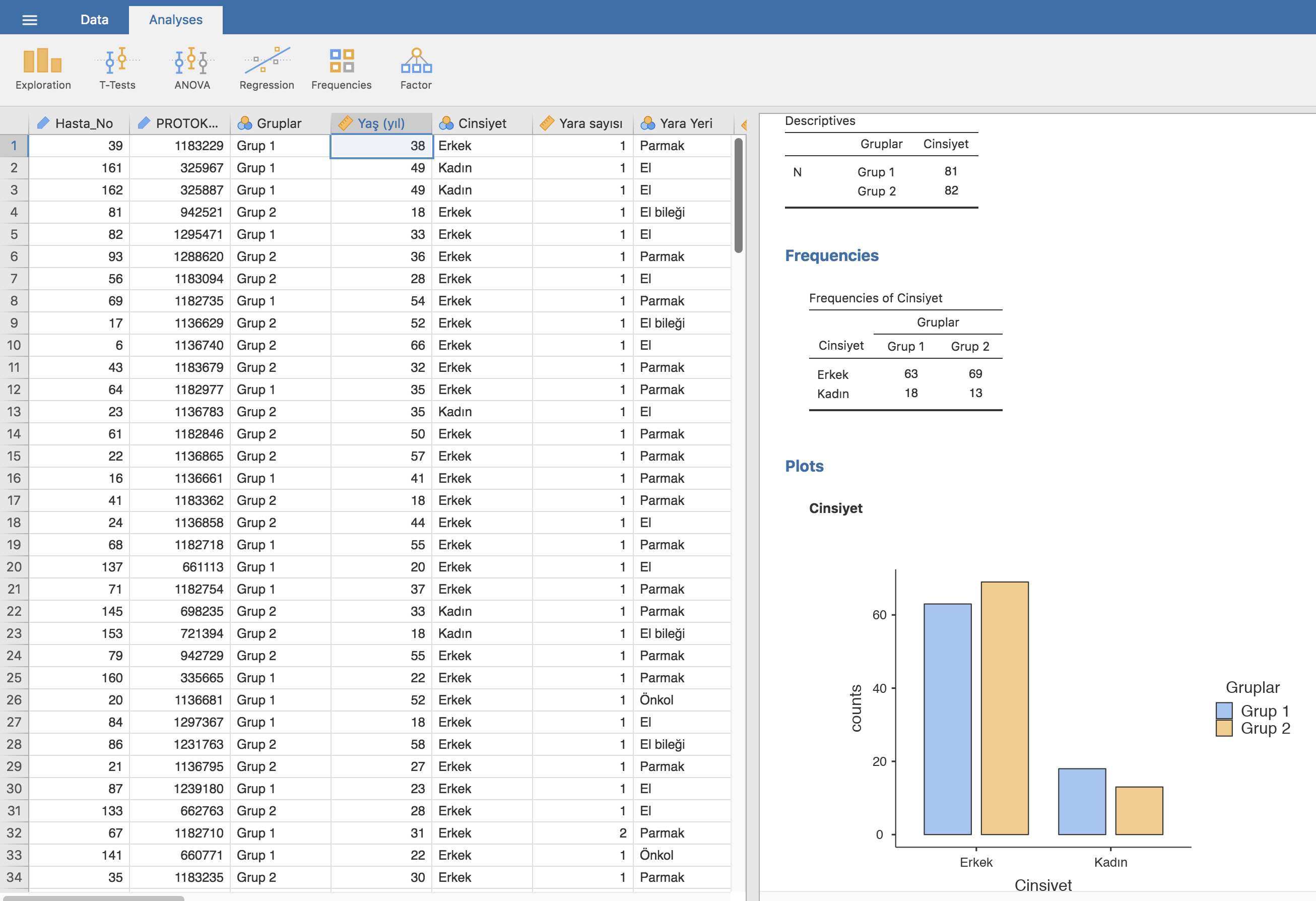
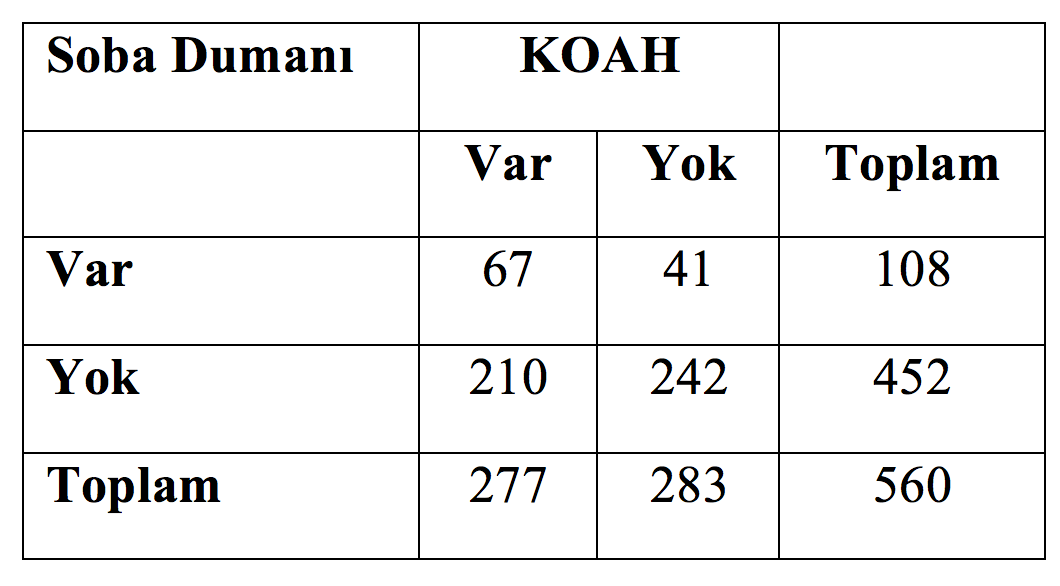
Literatürün çoğunu oluşturan gözlemsel çalışmalar [4] karşılaştırma veya kontrol grubu olup olmamasına göre sınıflandırılır. Bu tip bir karşılaştırma öğesi bulunan gözlemsel çalışmalara analitik, olmayanlara tanımlayıcı çalışma adı verilir. Analitik çalışmalarda maruziyet ve sonlanımların sırası çalışmanın alt tipini belirler. Bizim etkin olmadığımız (yani bizim uygulamadığımız) bir maruziyete uğramış vakaları alıp sonrasında sonlanım gelişen ve gelişmeyen vakaları karşılaştırıyorsak buna kohort çalışma adı verilir. Kohort çalışmalar eşzamanlı olabilir ya da olmayabilir. Gelişmiş olan sonlanımlara sahip vakaları geriye doğru tarayıp belirli bir maruziyete sahip olma ve olmama durumlarını karşılaştırıyorsak vaka-kontrol çalışması, hem maruziyet hem de sonlanım varlığını aynı zaman diliminde beraber gözlemleyip karşılaştırıyorsak kesitsel bir çalışmadan bahsediyor oluruz.
Araştırma hiyerarşisinin en altında tanımlayıcı çalışmalar gelir. Vaka sunumu bunun en basit örneğidir. Birden çok vakanın bir araya getirildiği sunumlara ise vaka-serisi adı verilir.
Tanımlayıcı çalışmalar
Araştırma hiyerarşinin en altında gelen tanımlayıcı çalışmalar ile araştırmacılar bir hastalık ya da durumun frekansını, doğal gidişatını ve muhtemel etkileyicilerini tanımlarlar. Bu çalışmaların sonuçlarından belirli bir zaman içinde kaç kişinin bu hastalık ya da duruma sahip olduğunu, etkilenenlerde hastalığın gidişat ve özelliklerini öğrenebiliriz.
Tanımlayıcı çalışmalar bilimsel bilgi havuzuna dökülen ilk damlalar gibidir. Konu edilen hastalık ya da durumun net, ayrıntılı ve ölçülebilir bir şekilde tanımlanmış olması şarttır. Klasik olarak tanımlayıcı bir tıbbi rapor kişi, yer ve zaman bilgisini; yani ajan, konakçı ve ortam bilgisini vermelidir. Bu klasik tanımlamayı biraz daha ileri götürürsek, modern bir tanımlayıcı araştırmanın tıpkı iyi bir gazetecinin yaptığı gibi Kim, Ne, Neden, Nasıl, Nerede ve Ne zaman sorularından oluşan 5N1K setinin bütününü cevaplaması gerektiğini söyleyebiliriz [2,5,6]. Bu 6 soruya bir de 7. soru olarak “peki ya şimdi” sorusunu eklemek ve buna yanıt vermeye çalışmak da tanımlayıcı çalışmanın ardından gelecek, taksonomide daha yüksek kanıt düzeyine sahip çalışmalara altyapı oluşturur. Yazarlar bu işlemi muhtemel sebepler ve sonuçlar hakkında teorilerini ortaya atarak yaparlar. Bu teorilerin karşılaştırmalı analitik ya da deneysel metodlarla ispatlanması gereklidir.
Tablo 1. Tanımlayıcı araştırmaların bildiriminde yanıtı verilmeye çalışılan sorular
| Soru | İçerik |
| Kim? | Hastalığa sahip olanlar kim? |
| Ne? | Çalışılan ya da bildirilen hastalık ne? |
| Neden? | Neden bu hastalık ya da durum gelişti? |
| Nasıl? | Nasıl ilerler ve kendini gösterir? |
| Nerede? | Nerede ortaya çıkar? |
| Ne zaman? | Ne zaman ortaya çıkar veya daha sık görülür? |
| Peki ya şimdi? | Neden bu hastalık önemli? |
Vaka sunumları, vaka serileri, sürveyans çalışmaları, ekolojik korelasyon çalışmaları, trend analizleri, sağlık planlamaları tanımlayıcı çalışmaların bütününü oluşturur. Ancak bu çalışmalar sebep-sonuç ve benzerleri gibi herhangi bir ilişki hakkında yorum yapmaya izin vermez. Tanımlayıcı çalışmalarla ilgili en sık yapılan hata da bu şekilde çıkarımlarda bulunmaktır.
1. Vaka sunumları
Bir gözlemcinin nadir bir hastalık, durum ya da ilişkiyi bildirdiği raporlardır. Bu raporlar tek bir hastaya ait tıbbi bir öyküyü bir düzen içinde sunan makalelerdir. Aynı hastalığa ait birkaç vaka sunumu bir araya getirilerek vaka serileri olarak da sunulabilirler. Kanıt düzeyi düşük olmakla birlikte bazen çok önemli yan etkilerin veya hastalıkların tanımlanması bir olgu sunumunun duruma dikkati çekmesi ile başlayabilir. Bu duruma örnek olarak talidomid kullanan bir annenin her iki bebeğinin de fokomeli ile doğduğunu fark ederek bu durumu bir vaka sunumuna dönüştüren doktorun diğer meslektaşlarında oluşturduğu farkındalığı gösterebiliriz.[7] Bildirilen vaka sunumları daha ileri tekniklerle yapılan çalışmalar için altyapı oluşturur.
2. Vaka serileri
Benzer vakaları bir araya getiren raporlardır. Bazen bir epidemi ya da bölgesel birikimi göstererek ileri incelemelerin başlatılmasına yardımcı olurlar.
3. Sürveyans
Halk sağlığı pratiğinde sağlık planlamaları, uygulamaları ve değerlendirmeleri için gereken sağlık verilerinin belirli zaman aralıklarıyla sistematik biçimde toplanması, analizi ve yorumlamasını takiben bu verileri kullanacaklarla paylaşılmasıdır. Pasif sürveyans Ölüm Bildirim Sistemi (ÖBS) gibi bir kayıt sisteminde otomatik olarak elde edilen verileri birleştirirken, aktif sürveyans ile belirli bir vaka çeşidi özel olarak araştırılır ve incelenir. Sürekli sürveyans ve aşılama sayesinde su çiçeği hastalığının eradikasyonunun sağlanması, epidemiyolojik sürveyansın önemine en güzel örnektir.
4. Ekolojik korelasyon çalışmaları
Ekolojik korelasyon çalışmaları maruziyet ve sonlanımlar arasındaki ilişkiye, bireyler üzerinden değil toplumlar üzerinden bakar. Koroner arter hastalığından ölüm sayısı ile kişi başına satılan sigara sayısı arasındaki ilişki gibi, halihazırda toplanan verilerin birbiri ile ilişkisini sayısallaştırmayı amaçlar. En önemli eksiklik tüm tanımlayıcı çalışmalarda olduğu gibi sebep-sonuç ilişkisinin kurulmasının mümkün olmamasıdır. Aynı şekilde koroner arter hastalığıyla renkli televizyon satışları arasında da yüksek bir ilişki belirlenmiştir. Televizyonda gösterilen saldırganlık ile okul içi saldırganlık arasında da güçlü bir ilişki vardır. Bu tip ilişkilerden hangisinin gerçek hangisinin karıştırıcı olduğu ileri tekniklerle analiz edilmelidir.
Analitik Çalışmalar
Analitik çalışmalar ise vaka-kontrol çalışmaları, kohort (prospektif/retrospektif) çalışmalar ve kesitsel çalışmalar olarak özetlenebilirler.
Vaka-kontrol tipi çalışmalarda daima retrospektif (geçmişteki sonuçlara bakılarak yorumlanan) “Ne oldu?” sorusuna yanıt aranır. Bu araştırmalar neden-sonuç ilişkisini irdeler. Çalışmanın bir kohort tipi araştırma olup olmadığını anlayabilmek için ise “Ne olacak?” sorusuna yanıt verip vermediğine bakılabilir.
Çoğu kohort tipi çalışma prospektif olarak (gelecekte gerçekleşecek sonuçların incelenmesi) yapılandırılmıştır. Bu çalışmalarda insidans ve rölatif risk gibi çok değerli verilere ulaşılır. Olası risk etmeninin gerçekten önemli olup olmadığı anlaşılır.
Kesitsel bir çalışmada ise “Ne oluyor?” sorusu yanıtlanır ve toplumdaki bir sağlık sorununu tespit etmek genellikle amaçtır. Genellikle hastalık prevalansı (sıklığı), hastalık mekanizmaları ve tanısal sorunların çözümü için yapılan bu çalışmalara güzel bir örnek, ülkemizdeki kalp hastalıklarına neden olan hipertansiyon, diabetes mellitus gibi hastalıkların prevalansının tespiti ile yaş ve cinsiyetle ilişkisinin incelendiği TEKHARF çalışmasıdır. [8,9]
Deneysel Çalışmalar
Bu çalışma dizaynında ilaç vermek ya da bir girişim uygulamak gibi bir şekilde biz bir şeyler yaparız. Böylece yaptığımız uygulamanın sonuçlarını değerlendirme imkanımız olur. Dolayısıyla, araştırmacı maruziyetleri kendisi oluşturuyorsa deneysel, kendi etkisi olmayan maruziyetler üzerinden araştırma yapıyorsa gözlemsel bir çalışma yürütmektedir diyebiliriz. Burada maruziyet, sonlanım üzerinde etkisi araştırılan her türlü olay, girişim ya da ilaç olabilir. Sonlanım ise fayda-zarar etkisinin hesaplanması için kullanılan, bir oran ya da ölçüyle ifade edilebilen her türlü bulguya işaret eder.
Klinik araştırma
Deneysel araştırmalar insanlar üzerinde yapılıyorsa bunlara klinik araştırma adı verilir. Örneğin, girişimsel sedo-analjezide kullanılan farklı ilaçların etkilerini karşılaştırma amacıyla dizayn edilen deneysel çalışma bir klinik araştırma, kullanılan farklı ilaçların her biri araştırmacı tarafından belirlenmiş farklı birer maruziyet, sedasyon süresi, analjezi derinliği ya da hasta memnuniyeti de sonlanımlardır. Bazı nüanslar dışında deneylerde geçerli kuralların hepsinin klinik araştırmalar için de geçerli olduğu söylenebilir.
Bağımsız eşzamanlı kontrollü araştırma
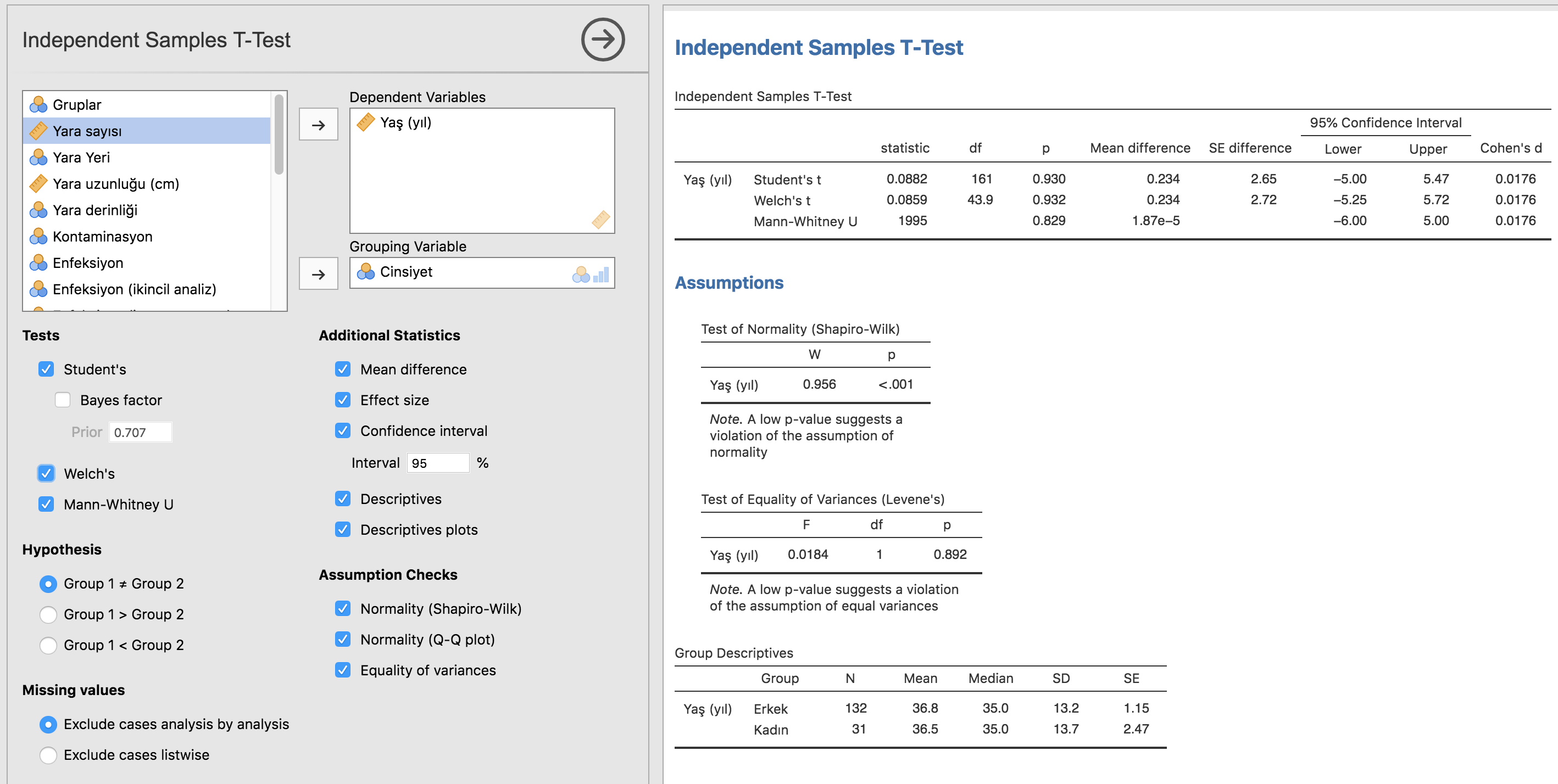
Ana yapı olarak dörde ayrılan deneysel araştırmaların en önemli gruplarından biri bağımsız eşzamanlı kontrollü araştırmalardır. Bu araştırmalar bir deney grubu ve kontrol grubu içerirler. Eğer hastanın hangi gruba alınacağı rastgele bir yöntemle saptanıyorsa bu araştırma randomize kontrollü bir araştırma olacaktır. Deneklerin gruplara alınma yöntemi önceden belirlenmiş ise randomize olmayan kontrollü bir çalışma dizayn edilmiştir. Eğer hem denekler hem de araştırmacılar deneğin hangi grupta olduğunu bilmiyorlarsa çift, sadece denekler hangi yöntemin uygulandığını bilmiyorlarsa tek-kör araştırmadan söz edilir. Çift kör, randomize kontrollü araştırmalarda elde edilen veriler daha objektif oldukları için kanıt düzeyleri güçlü olarak değerlendirilirler.[8] Bu çalışmalar bir ilaç ya da girişimin sınanacağı deneylerde kullanılırlar. Kendi kendine kontrollü araştırmalar ise deney ve kontrol grupları içinde farklı denekler bulunduğu durumlarda randomizasyona rağmen gruplar arasında istenilen benzerliği sağlanamadığı durumlarda tercih edilirler. Çözüm olarak denekler hem deney hem kontrol grubunda yer alırlar. Örneklersek; serum kolestrol düzeyini düşürmede etkili olabilecek iki tür diyetin karşılaştırıldığı bir çalışmada obezite, ailesel lipid metabolizma bozuklukları gibi kontrol edilemeyen bireysel farklılıkları giderebilmek amacı ile hastalar önce hem kontrol hem de deney grubunda yer alırlar. Önce-sonra tipindeki bu araştırmalar da ilk önce normal diyetle beslenen bir hasta grubu serum kolestrol düzeyi ölçülür, sonrasında ise bu düzey diyet tipine göre bir süre sonra aynı grupta ölçülerek karşılaştırılır.[9]
Çapraz Dizayn
Diğer bir deneysel araştırma yöntemi ise çapraz dizayn çalışmalardır. Bu araştırma düzeninde başlangıçta oluşturulan iki bağımsız gruptan birine araştırılan yöntem veya ilaç uygulanır diğerine ise plasebo verilir. Bir süre sonra etkiler kaydedilir ve uygulanan yönteme (eğer ilaç ise an az yarılanma ömrünün 4 katı kadar ara verilerek – arınma periyodu) gruplar çaprazlanır. Bu araştırma sonuçları oldukça güvenilir ve güçlü olarak kabul edilirler. Ancak arınma durumunda ilaçsız kalma pek çok klinik durum için uygun ve etik olmayabilir. Son olarak dış kontrollü araştırmalar da deneysel araştırmalardandır. Bu araştırmalarda kontrol grubu başka bir araştırma grubuna veya daha önce uygulanan bir yönteme ait olabilir. Örneklemek gerekirse; portal hipertansiyon için uygulanan bir cerrahi yöntemin sonuçlarının on yıl önceki eski yöntemin uygulandığı hasta grubu ile karşılaştırılması.[8]
Metodolojik Çalışma
Diğer araştırma tipleri ise metodolojik araştırmalardır ve tanı ve tarama yöntemlerinin geçerliliğine yönelik çalışmalar, gözlemcilerin ölçüm yöntemlerinin güvenilirliğine yönelik araştırmalar ve matematik simulasyon modelleri ile yapılan araştırmalar olarak sınıflanırlar.
Makalelerin konu temelinde sınıflaması
Araştırma makaleleri genellikle aşağıda verilen ana konulardan birine yönelik olarak yukarıda belirttiğimiz dizaynlarda planlanmış çalışmaların yayınlanmış halleridir.
Tedavileri inceleyen makaleler
Bir ilaç, cerrahi girişim veya alternatif hasta eğitim ya da uygulamaları gibi yöntemlerin etkinliğini inceleyen bu makaleler için tercih edilmesi önerilen araştırma şekli randomize kontrollü çalışmalardır.
Tanı yöntemlerine yönelik araştırmalar
Yeni bir tanısal yöntemin geçerli (bu teste güvenelim mi?) ve güvenilir (testi her tekrar ettiğimizde aynı sonuçlara mı ulaşırız?) olup olmadığını araştırmak için yapılan bu araştırmalar için önerilen yöntem ise yeni yöntemin ve altın standart yöntemin birlikte uygulandığı kesitsel çalışmalardır.
Taramalar
Bir testin presemptomatik durumdaki hastalarda tanı amaçlı kullanımını inceleyen çalışmalardır, önerilen çalışma dizaynı kesitsel tiptedir.
Prognoz saptayıcı araştırmalar
Bu araştırmalar erken dönemde herhangi bir hastalığı olan bireyin prognozunu inceler, önerilen araştırma tipi uzun süreli prospektif kohortlardır.
Nedensellik araştırmaları
Bu araştırmalar da ise çevresel kirlilik gibi zararlı bir ajanın neden olduğu hastalıklar incelenir. Önerilen araştırma yöntemleri kohort ya da olgu kontrol tipi araştırmalar olabileceği gibi ender görülen durumlarda (kot taşlama işçilerinde silikozis gibi..) olgu raporlarından da önemli ip uçları elde edilebilir.[7]
İkincil Çalışmalar
Kanıta Dayalı Tıp (KDT) uygulamalarında kullanılan kanıtların hiyerarşik dizilimlerinde en üst düzeyde sistematik derlemeler ve meta-analizler yer alır.[10] Bu çalışmaların yapılması esnasında belli aşamalardan oluşan bir metodoloji izlenir. Bu araştırmalar birincil tipte yürütülen araştırma verilerinin ikincil analizi şeklinde yürütülür. Sistematik derlemelerde bir protokol esasınca derlemeye alınacak yayınlar seçilir ve uygun çalışmaların bulguları yorumlanır. Sistematik derlemelerde her zaman istatistiksel analiz yapılması şart değil iken meta-analizlerde benzer tasarımı olan farklı çalışma bulgularından toplu olarak istatistiksel analiz yapılmaktadır. Bir meta-analiz, sistematik derleme metodolojisi ile çalışmaları seçmiş ise “sistematik bir meta-analiz” olarak değerlendirilir ve varılan sonucun kestirim gücü artar. Bu tipte yapılan araştırmalarda birçok çalışma bir araya getirilerek hem örneklem büyüklüğü hem de istatistiksel güç arttırılır. Seyrek görülen hastalıklar daha büyük gruplarda incelenebilir.
Bir makalenin sistematik derleme mi yoksa meta-analiz mi olduğuna karar verebilmek için bizi meta-analiz yönünde düşündürecek olan şu kıstaslara dikkat edilir:
- Önceden belirlenmiş bir amaca uygun olarak araştırma protokolü belirlenmiş mi?
- Analize alınan çalışmaların çalışmaya dahil etme ve etmeme kriterleri var mı?
- Seçilen yayınlardan elde edilen verilerin hangi istatistiksel yöntemler ile yeniden analize tabii tutulduğu belirtilmiş mi?
- Elde edilen sonuçlar tıpkı bir araştırma makalesi gibi IMRAD yapısında mı yazılmış?
Bilimsel Kanıtların Değerliliği
Makalelerin bilimsel kanıt düzeylerine göre dizilimi ise içerdikleri bilgi yükü ve objektif yönteme sahip olmalarına göre belirlenmiş geleneksel bir sıralamaya sahiptir. Bu sıralamaya göre en değerli bilimsel kanıtlar sistematik derlemeler ve meta-analizlerden elde edilirler. Bu çalışmaların değerli olmasının nedeni belirlenmiş bir yöntem doğrultusunda birden fazla örneklem grubunda elde edilen verilerin bir arada yorumlanması olarak özetlenebilir. İkinci sırada değerli kanıt kaynakları ise kesin tanımlayıcı sonuçlara işaret eden (güven aralıkları kesişmeyen klinik anlamlı etki düzeyleri gibi..) randomize kontrollü çalışmalardır. Üçüncü sırada ise yine randomize kontrollü çalışmalar bulunmakla birlikte bu çalışmalardan elde edilen kesinleşmiş tanımlayıcı sonuçlar bulunmaz. Randomizasyon ve tanımlanmış deney ve kontrol gruplarının bulunması bu çalışmaların yöntemsel hata yapma olasılığını azalttığı için çalışmalarda elde edilen veriler değerli olmaktadır. Daha sonraki sırada ise kohort çalışmaları, olgu kontrol tipi araştırmalar, kesitsel çalışmalar ve en sonda ise olgu sunumları yer almaktadır.[7]

Kaynaklar
- Guyatt G. Users’ Guides to the Medical Literature: A Manual for Evidence-Based Clinical Practice, 3E. McGraw Hill Professional 2014.
- Schulz KF, Grimes DA. The Lancet Handbook of Essential Concepts in Clinical Research. The Lancet 2006.
- Hulley SB, Cummings SR, Browner WS, Grady DG, Newman TB. Designing Clinical Research. Lippincott Williams & Wilkins 2013.
- Funai EF, Rosenbush EJ, Lee MJ, Del Priore G. Distribution of study designs in four major US journals of obstetrics and gynecology. Gynecol Obstet Invest 2001;51:8–11.
- Buring JE. Epidemiology in Medicine. Lippincott Williams & Wilkins 1987.
- Lilienfeld DE. Lilienfeld’s Foundations of Epidemiology. Oxford University Press, USA 2015.
- Greenhalgh T. How to Read a Paper. John Wiley & Sons 2014.
- Hayran M. Sağlık Araştırmaları İçin Temel İstatistik. Omega Araştırma 2011.
- Onat A. Lipids, lipoproteins and apolipoproteins among turks, and impact on coronary heart disease. Anadolu Kardiyol Derg 2004;4:236–45.
- Jones C. Evidence-based medicine: (1) Research methods. Pharmaceutical Journal 2002;268:839–41.